최종 프로젝트 인프라 구축⑩ - EFK 서비스 모니터링
EFK 모니터링
지난 시간에 node exporter, prometheus와 grafana를 사용한 시스템 모니터링 환경을 구축하였는데,
이번에는 시스템 내 서비스를 모니터링하는 EFK 시스템를 만들어보겠다.
참고로 EFK를 구축한 것은 서비스가 주식 거래와 같은 블록체인 토큰 거래를 하기 때문에,
거래마다 로그를 남겨 해당 거래가 이상 거래인지를 탐지하기 위해서이다.
(이상 거래는, 사정상 1초에 1000번 거래–, 12시에 8만주 수매– 같이 딱 봐도 수상한 기준으로 삼았다)
EFK 시스템은 ElasticSearch, Fluentd, Kibana로 구성된 기술로, 가동 원리는 이전 시스템 모니터링과 거의 동일하다. 즉
- Fluentd가 노드에 붙어 서비스 로그를 수집, 시스템의 node-exporter/cadvisor 등에 해당
- ElasticSearch가 그걸 모아다 분석, 시스템의 prometheus에 해당
- Kibana가 위 내용을 UI화, 시스템의 grafana에 해당
이제 이해되었죠? 바로 넘어가 봅시다.
Elasticsearch, kibana 설치

(매일 지우고 설치하는 EC2라 IP가 노출되도 상관x)
우선 지난번처럼 로컬 서버 포화 문제로 로컬엔 서비스에 붙어야 하는 Fluentd만 남기고, Elastic와 Kibana 서비스는 EC2에서 하도록 하겠다.
그래서 사진처럼 퍼블릭 써브넷에 EC2를 만들어주었다.
Elastic 특성상 시스템 자원을 많이 잡아먹기 때문에 인스턴스는 t3.medium
Elasticsearch 설치
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat <<EOF | sudo tee /etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
sudo dnf install install elasticsearch -y
...
sudo systemctl enable --now elasticsearch
systemctl status elasticsearch
아마존 리눅스 2023은 기본적으로 yum에 elastic 레포가 없기 때문에 위 명령어처럼 레포를 만들어주고 설치해야 한다.
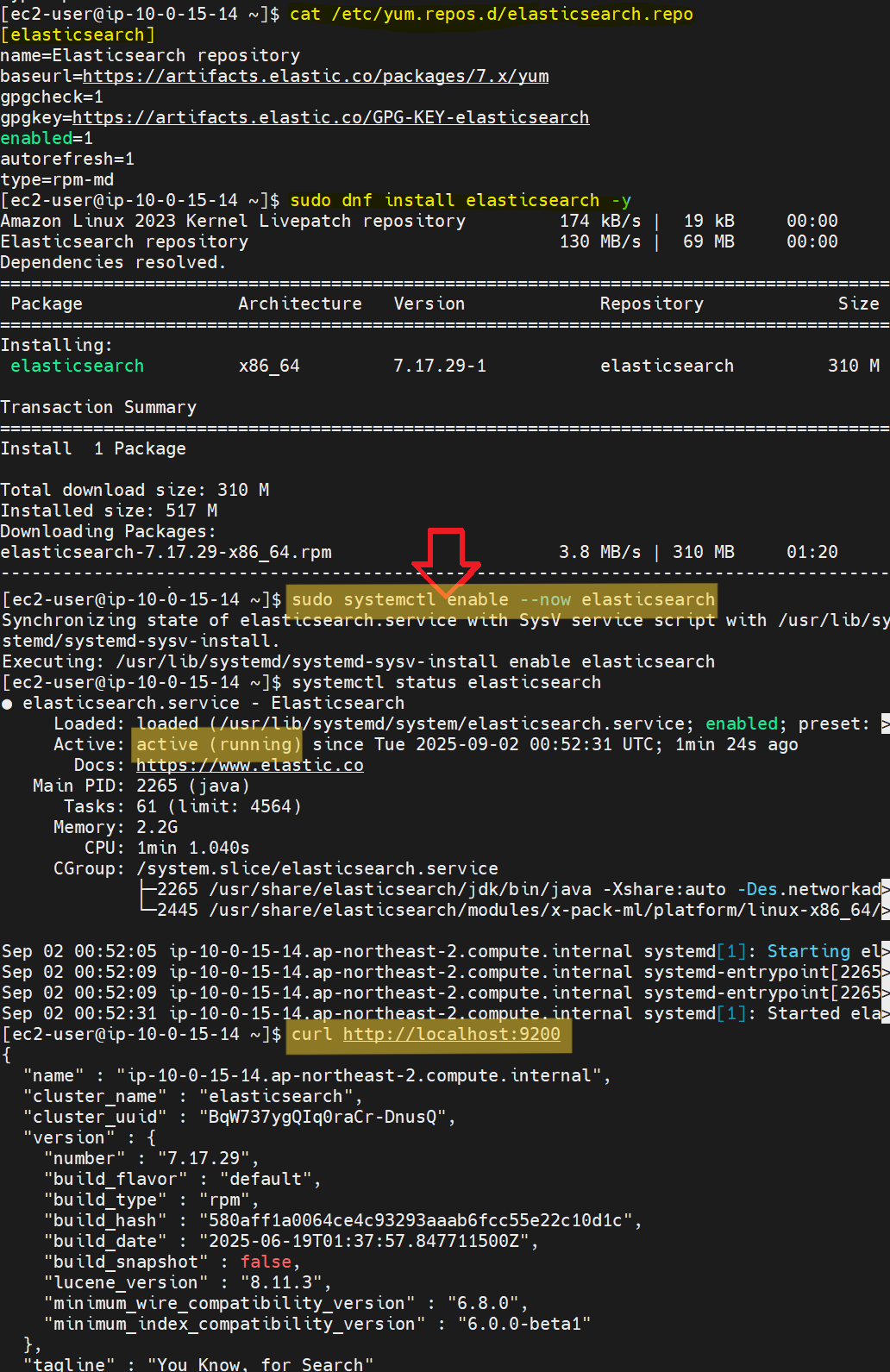
dnf 설치가 끝나고 위 사진처럼 systemctl status elasticsearch했을 때 running이면 정상~
키바나 설치
1
2
3
sudo dnf install kibana -y
sudo systemctl enable --now kibana
systemctl status kibana
키바나는 기본적으로 레포에 있어서, 그냥 dnf install하면 끝!
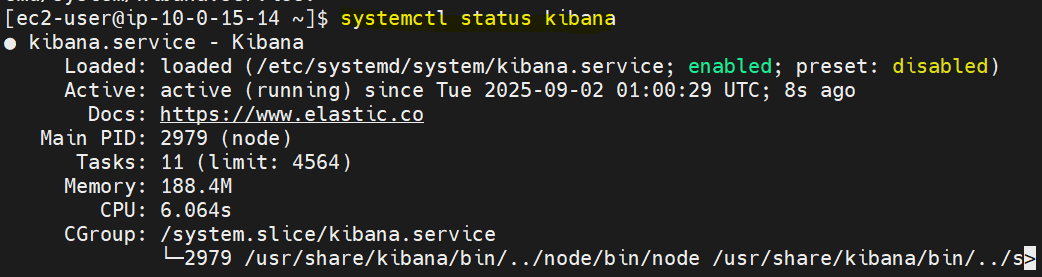
서비스 및 보안그룹 설정
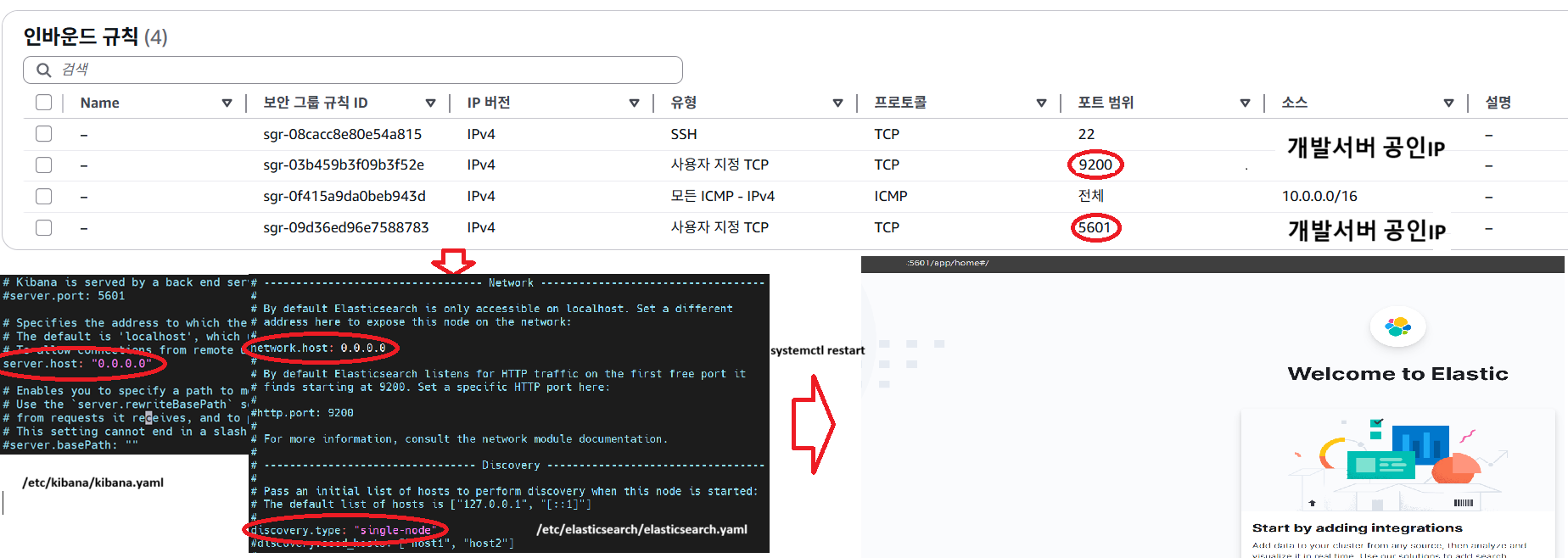
키바나와 엘라스틱이 모든 IP를 받도록
키바나 설정화일인 /etc/kibana/kibana.yaml에
1
2
3
...
server.host: "0.0.0.0"
...
이렇게 추가해줘야 한다. 0.0.0.0이면 IP 전부 허용 아냐? 보안 문제! 이럴 수 있겠지만 어차피 IP 허용/차단은 EC2 보안그룹에서 하니까
엘라스틱도 /etc/elasticsearch/elasticsearch.yaml에서
1
2
3
4
...
network.host: 0.0.0.0
...
discovery-type: "single-node"
이렇게 해 주는데, 저 discovery-type은 엘라스틱서치도 클러스터를 구성할 수 있다.
당직(当職) 서비스처럼 조그만 거면 모를까, 기업 단위의 솔루션은 여러 서비스에서 엄청난 양의 로그가 매초 수집되기 때문에 클러스터 구성은 필수다.
근데 당직은 그럴 필요가 없으니 single-node로 하여 이 서버만 엘라스틱을 돌리도록 하는 것~
양쪽 수정이 끝났으면
systemctl restart kibana
systemctl restart elasticsearch
로 재시작해야 바뀐 설정이 적용된다.
그리고 보안그룹 설정은 이제 말 안해도 알겠죠~?
elastic용 9200, kibana용 5601 포트 열어주셔야 합니다. Fluentd는 EC2로 보내기만 하기 때문에(아웃바인딩) 공유기 포트포워딩은 필요없어요
Fluentd 설치
플루언트디는 좀 많이 해맸다. 이것도 지난번의 kube-state-monitoring 설치 때처럼 쿠버 pod에 붙기 때문에, serviceaccount와 같은 복잡한 설정을 해 줘야 한다.
거래 로그
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"timestamp":"2025-09-03T05:15:54.637866396Z",
"@version":"1",
"message":"purchase log captured.",
"logger_name":"com.(검열됨).backend_market.trade.service.TradeService",
"thread_name":"http-nio-8086-exec-1",
"level":"INFO",
"level_value":20000,
"tokenQuantity":"2",
"orderId":"44",
"purchasePrice":"1000",
"projectId":"68b79d31dc3f0dd37c56168d",
"userSeq":"b32632f0-1634-4f3f-91e0-7f4161e81610",
"ordersType":"1",
"application":"com.(검열됨).backend_market"
}
현재 거래 로그는 이렇게 되어 있다. 백엔드와 함께 logback이라는 것을 사용해 구현했는데,
블록체인 토큰 구매/판매/취소시 message에 purchase/sales/cancel log captured로 구분해 로그를 남긴다.
당직은 이렇게 되어 있는 로그만 수집할 것이라, 일단 구조를 익혀 두자.
configmap
참고로 모니터링 때 관련 yaml들의 네임스페이스를 monitoring으로 정한 것처럼, 이번에는 logging이라는 네임스페이스를 사용할 것이다.
따라서 그대로 따라할 거면 kubectl create namespace logging은 필수~
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: logging
data:
fluent.conf: |
<source>
@type tail
@id in_tail_container_logs
path /var/log/containers/*market*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type cri
<parser>
@type json
</parser>
</parse>
</source>
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<filter kubernetes.**>
@type parser
key_name message
<parse>
@type json
</parse>
remove_keys ["message"]
</filter>
<match kubernetes.**>
@type elasticsearch
@id out_es
host (엘라스틱 서버 주소)
port 9200
scheme http
logstash_format true
include_tag_key true
flush_interval 5s
</match>
이것은 fluentd 셋팅에 가장 중요한 configmap 화일로, xml 형식으로 된 .conf 화일로 fluentd의 로그 수집을 관리하는데,
<source>는 로그를 어떻게 읽을지를 설정한다.@type은 로그 화일의 읽는 방법을 설정한다. 보통 스트림 방식으로 읽는tail을 사용@id는 이 읽는 방식의 이름 변수인데, 나중에 다른 로그들도 읽어야할 때 구분을 위해 사용한다.path에서 수집할 로그 화일을 지정할 수 있다. 쿠버 로그들은/var/log/containers위치에 저장되고, 위 로그는market서비스의 로그이기 때문에*market*.log이렇게 지정해 주었다.pos_file은 로그 끊김 방지를 위한 화일tag는<source>의 이름 변수, 아래<filter>나<match>등에서 구분하기 위해 사용한다.<parse>아래 항목은 쿠버 로그의 기본 형식인 cri를 json으로 변환하기 위한 설정이다.read_from_head는 fluentd를 켰을 때 로그화일의 시작부터 읽을지 여부를 정한다.<filter>는 읽어온 로그를 가공 하는 설정이다. 뒤에kubernetes.**을 붙여<source>tag가kubernetes.*인 것들만 설정한다.- 첫 번째
<filter>는 로그에 쿠버 메타데이타(컨테이너명,pod명,네임스페이스 등…)을 붙여주는 설정이고 - 두 번째
<filter>는 로그의message항목을 JSON 파싱해 각 키/값들을 로그에 추가한 뒤, 필요 없어진message항목은 삭제하는 과정이다.
이게 무슨 말이냐면 위에서 보여준 로그가 수집될 때, 저 JSON 형식 그대로 수집되는 것이 아니라 저 로그를 message 항목에 담아 두고 다른 것들을 붙이는데, 백문이 불여일견으로
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"application": "aaa",
"application.keyword": "bbb",
"level": "INFO",
...,
"message": {
"timestamp":"2025-09-03T05:15:54.637866396Z",
"@version":"1",
"message":"purchase log captured.",
"logger_name":"com.(검열됨).backend_market.trade.service.TradeService",
"thread_name":"http-nio-8086-exec-1",
"level":"INFO",
"level_value":20000,
"tokenQuantity":"2",
"orderId":"44",
"purchasePrice":"1000",
"projectId":"68b79d31dc3f0dd37c56168d",
"userSeq":"b32632f0-1634-4f3f-91e0-7f4161e81610",
"ordersType":"1",
"application":"com.(검열됨).backend_market"
},
"thread_name": "ccc",
...
}
이렇게 되어 있던 것이 저 필터를 만나면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
"application": "aaa",
"application.keyword": "bbb",
"level": "INFO",
...
"timestamp":"2025-09-03T05:15:54.637866396Z",
"@version":"1",
"message":"purchase log captured.",
"logger_name":"com.(검열됨).backend_market.trade.service.TradeService",
"thread_name":"http-nio-8086-exec-1",
"level":"INFO",
"level_value":20000,
"tokenQuantity":"2",
"orderId":"44",
"purchasePrice":"1000",
"projectId":"68b79d31dc3f0dd37c56168d",
"userSeq":"b32632f0-1634-4f3f-91e0-7f4161e81610",
"ordersType":"1",
"application":"com.(검열됨).backend_market",
"thread_name": "ccc",
...
}
이렇게 된다는 것이다!
- 마지막
<match>는 이렇게 처리한 로그를 엘라스틱써치로 넘기는 설정이다. 마찬가지로 tag를 붙여 해당 로그만 수집되도록 host와port,scheme는 엘라스틱써치 서버의 주소와 포트, 통신방식을 넣으면 되고(기본 9200 포트, 현재 https를 사용중이지 않으므로 http)logstash_format은 이 로그의 인덱스(DB의 인덱스 그거)를 logstash 스타일로 만들 것이냐인데,true로 해 주면 키바나에서logstash-년월일형식으로 볼 수 있다.include_tag_key는 앞서<source>의tag값을 로그 항목에 넣을 것일지를 지정,flush_interval은 전송 간격
아무튼 이렇게 한 뒤 kubectl apply -f 해주면 된다.
여기 설정에서 굉장히 애를 먹었다.
<source>에 cri 타잎 설정을 안 해줘 elastic에 로그가 전송되지 않는다던가,
/var/log/container/ 권한 문제로 로그 화일을 읽을 수 없는다던가…
이는 아래에서 설명하겠다.
serviceaccount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: logging
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
rules:
- apiGroups: [""]
resources:
- pods
- namespaces
- nodes
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluentd
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluentd
subjects:
- kind: ServiceAccount
name: fluentd
namespace: logging
이 fluentd는 kube-state-metrics처럼 pod들에 직접 접근해야 하므로 이렇게 써비스 어카운트 권한 설정도 만들어 준다.
kubectl apply -f하는 것 잊지 말고~
daemonset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccountName: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch
env:
- name: FLUENTD_CONF
value: fluent.conf
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log/containers
- name: varlogpods
mountPath: /var/log/pods
- name: config-volume
mountPath: /fluentd/etc
securityContext:
runAsUser: 0
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log/containers
- name: varlogpods
hostPath:
path: /var/log/pods
- name: config-volume
configMap:
name: fluentd-config
items:
- key: fluent.conf
path: fluent.conf
시스템 모니터링 때와 마찬가지로 이 fluentd는 노드당 한 개씩 있어야 하므로 daemonset 방식으로 설정해 준다. node-exporter 때처럼 (fluentbit라는 것도 있는데, 이건 서비스 컨테이너 pod당 하나씩 들어간다. 일명 싸이드카 방식)
여기서 volumeMounts와 volumes에 주목하는데, 아까 말한 /var/log/containers 오류 관련해서
이 /var/log/containers는 심볼릭 링크, 즉 바로가기고 실제 위치는 /var/log/pods이다.
이 /var/log/pods를 마운트하지 않으면 fluentd가 /var/log/container에 들어가도 아무것도 발견하지 못할 것이니, 저 var/log/pods도 반드시 마운트해줘야 한다.
아무튼 이것도 kubectl apply -f를 해 주면
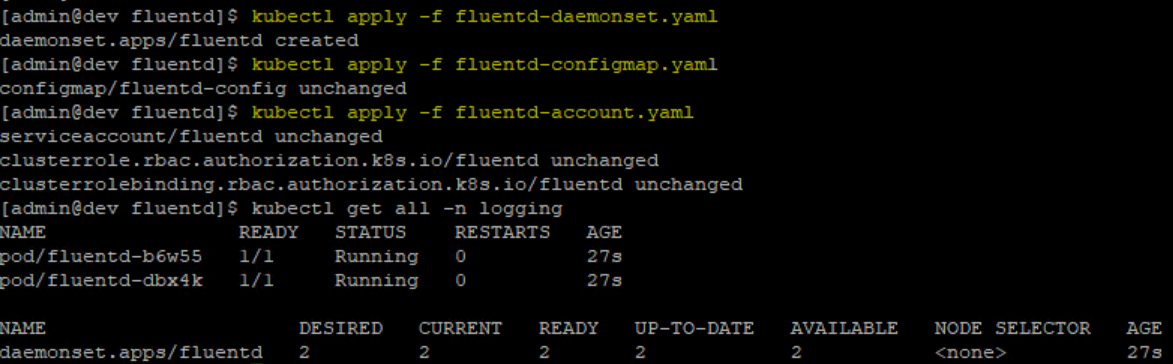
이렇게 fluentd pod가 Running이여야 정상이다! 당직은 이 Running을 보기 위해 한나절을 까먹었다…
키바나에서 모니터링
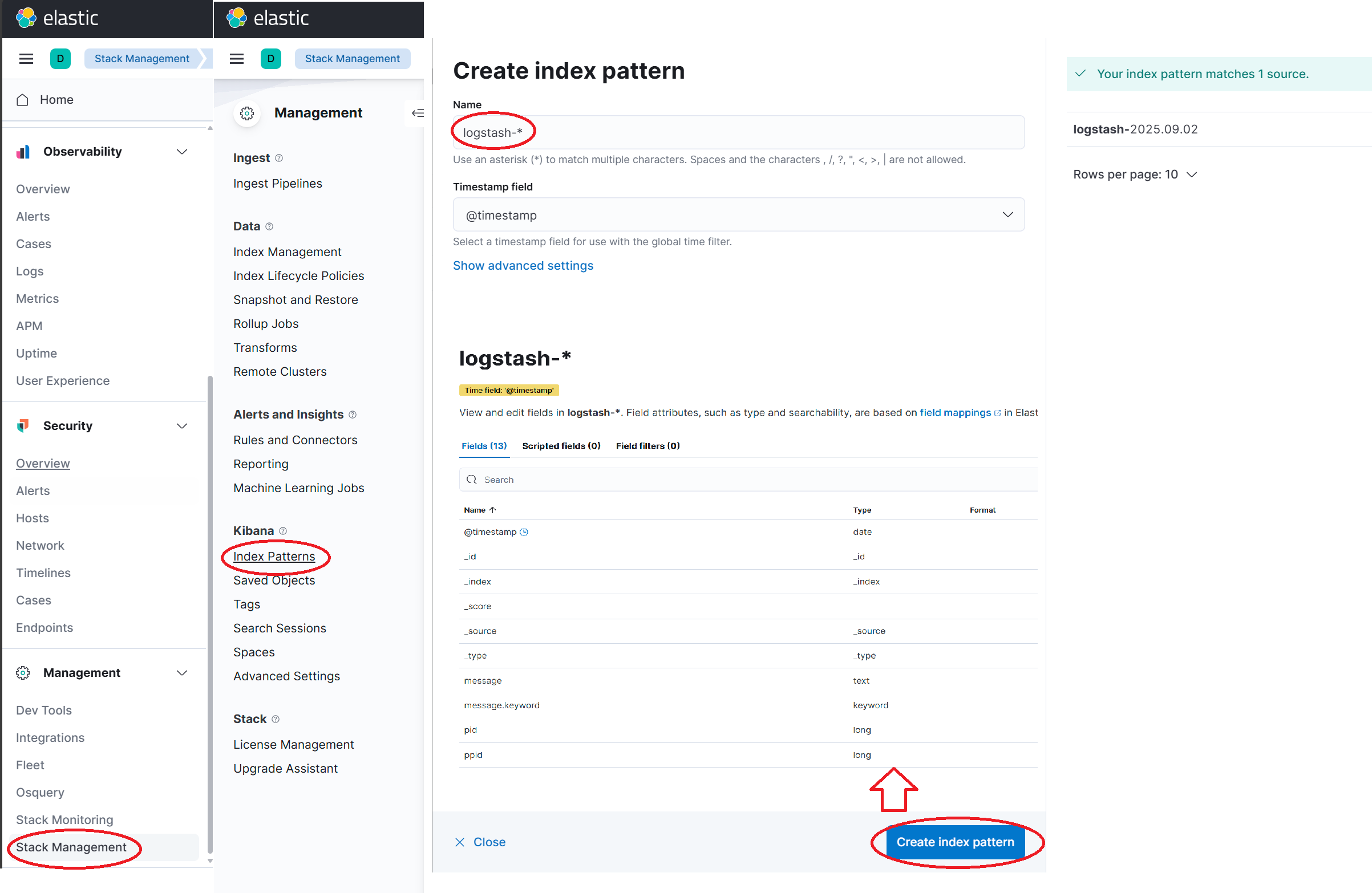
(엘라스틱 서버 IP):5601을 하면 kibana 대쉬보드에 접속할 수 있다.
여기서 왼쪽 바를 아래로 내려 Stack Management를 클릭하고,
새 창이 나오면 또 왼쪽 바의 Index Patterns를 선택하면 Create index pattern 창이 뜨는데,
여기서 아까 <match>에서 설정해 놓은 logstash_format이 빛을 발한다.
fluentd가 위 수집한 로그들을 logstash-년월일이라는 인덱스로 묶어놓은 것이다!
그래서 Name에 logstash-*(*는 년월일이니까) 이렇게 지정하고, Create index pattern 버턴을 클릭하면 이제 수집한 로그들을 UI에서 확인할 수 있다.
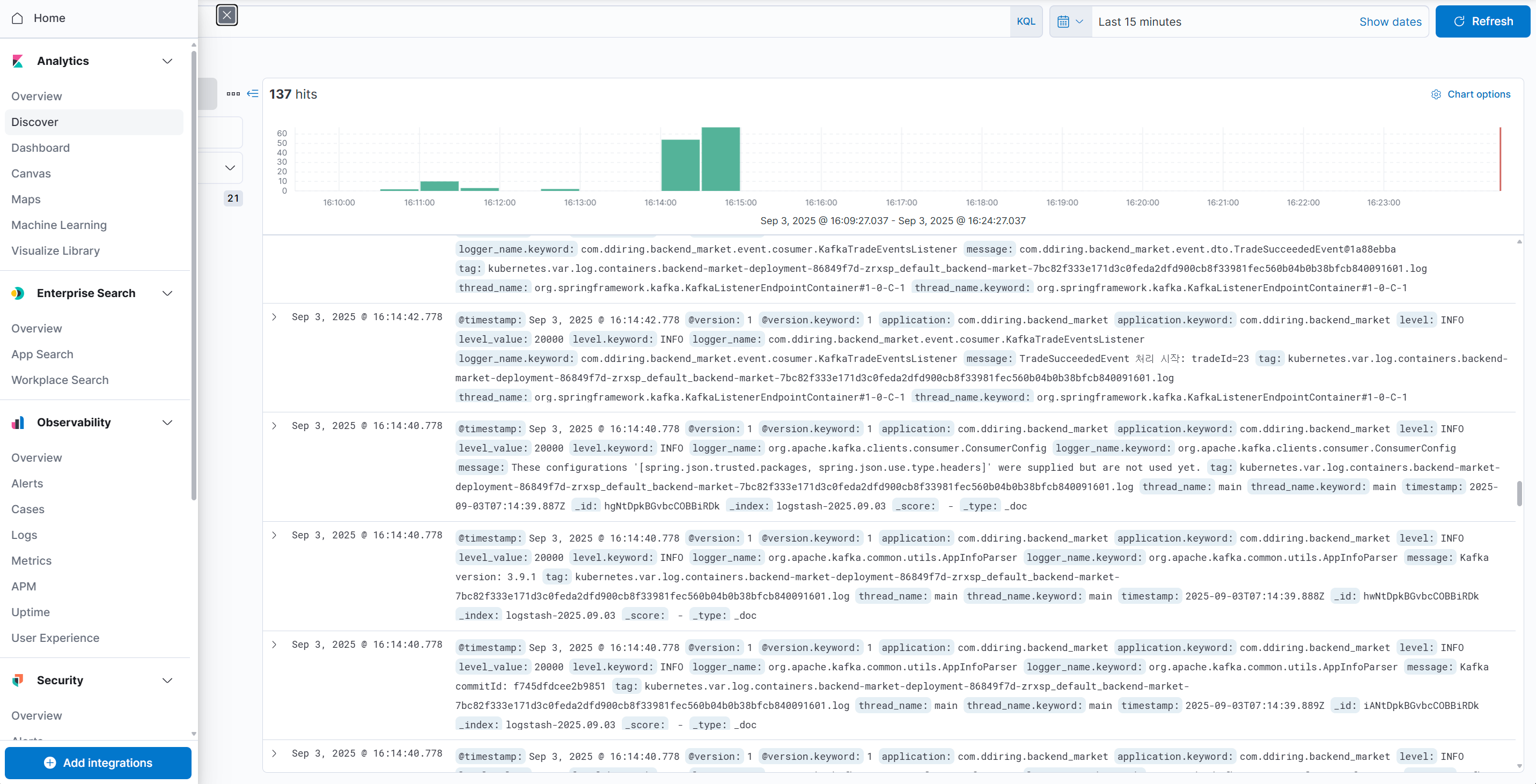
로그들이 쌓이는 것은 홈으로 가서 Analytics 탭의 Discover에서 확인할 수 있다.
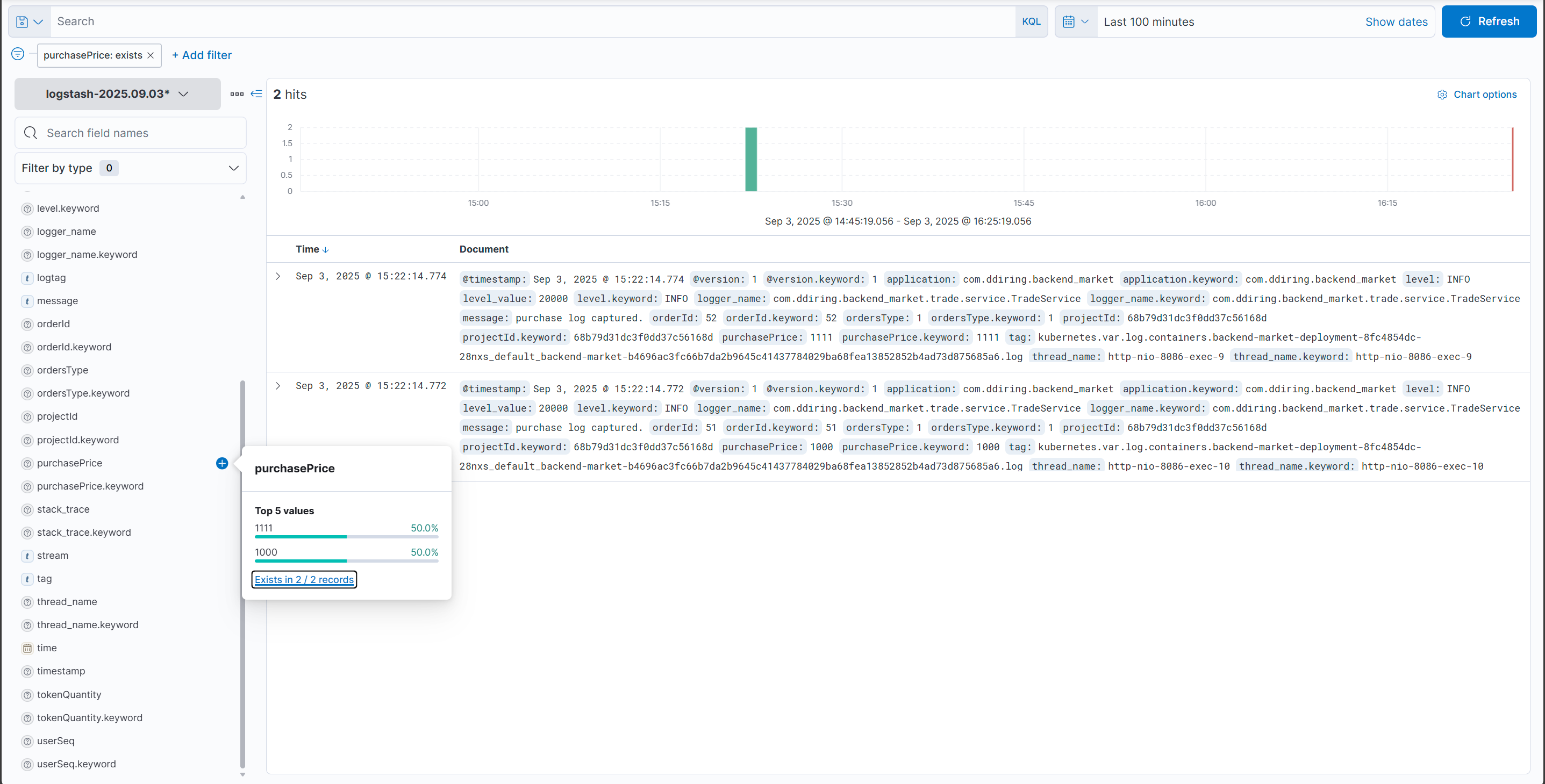
이렇게 필터링 기능도 제공하므로 이제 열심히 씹고 뜯고 맛보고 즐기면 된다!
번외편-로그 elastic 대신 kafka에 전달
원래는 이 엘라스틱써치로 로그를 모니터링하고, 이상 거래 기준에 맞으면 알림 등을 통해 프론트로 보내는 계획이었는데
시간이 얼마 없어 기능 구현을 하지 못할 뻔…하다가 백엔드 쪽에서 더 간편한 방법을 사용하기로 했다.
바로 기존 kafka 서비스를 사용, 어차피 로그는 JSON 형식이니 elastic에 보내는 대신 kafka에 던져 kafka stream을 사용해 백엔드에서 한 번에 처리하는 것이다.
따라서 당직은 fluentd 설정을 엘라스틱 대신 카프카에 맞게 재지정해줘야 했는데…
configmap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: logging
data:
fluent.conf: |
...
<filter kubernetes.**>
@type grep
<regexp>
key message
pattern (purchase|sales|cancel) log captured\.
</regexp>
</filter>
<match kubernetes.**>
@type kafka
brokers (카프카서버 주소):9092
default_topic fluentd_logs
<format>
@type json
</format>
flush_interval 5s
</match>
<source>는 그대로 두고, <filter>와 <match>를 위와 같이 수정했다.
- 쿠버 메타데이타를 지우고
- 무식하게 로그의
messages항목이pattern정규식에 맞는 것들만 수집하게 필터를 지정했으며 - 카프카에
fluentd_logs토픽으로 전달되도록 설정했다.
daemonset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
spec:
...
containers:
...
command: ["/bin/bash"]
args:
- "-c"
- |
gem install fluent-plugin-kafka --no-doc
exec fluentd -c /fluentd/etc/fluent.conf
terminationGracePeriodSeconds: 30
...
카프카와 fluentd를 연결하려면 fluentd pod에 fluent-plugin-kafka 팩키지를 설치해야 했다.
따라서 데몬셑 yaml에 pod에 fluent-plugin-kafka를 gem 설치하고(fluentd는 ruby 언어 기반입니다.)
fluentd를 저 (볼륨마운트 되어 있는)conf 설정으로 실행하는 –무식한– 명령어를 추가하였다.
저렇게 하면 pod가 실행될 때, 저 bash 명령어를 먼저 수행하는 것이다.
그래서 kafka에 잘 가는지를 시험해 보니…
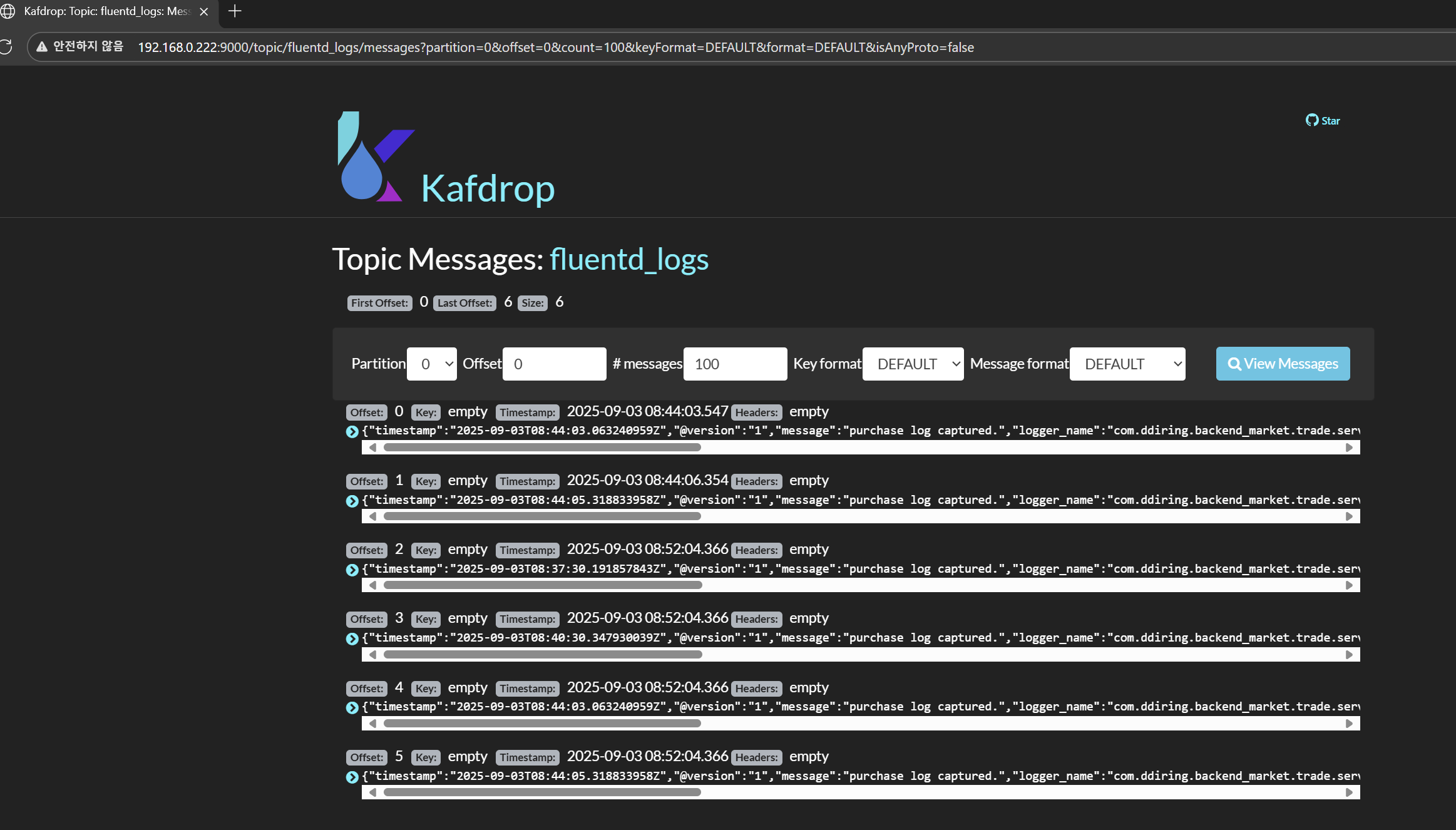
정말 다행히 한 방에 들어오는 걸 확인할 수 있었다!