최종 프로젝트 인프라 구축⑨ - 프로메테우스와 그라파나
시스템 모니터링하기
aws 그라파나 서버를 사용해 로컬 환경의 쿠버네티스와 컨테이너 서버(젠킨스)를 모니터링 해 보겠다.
작동 원리
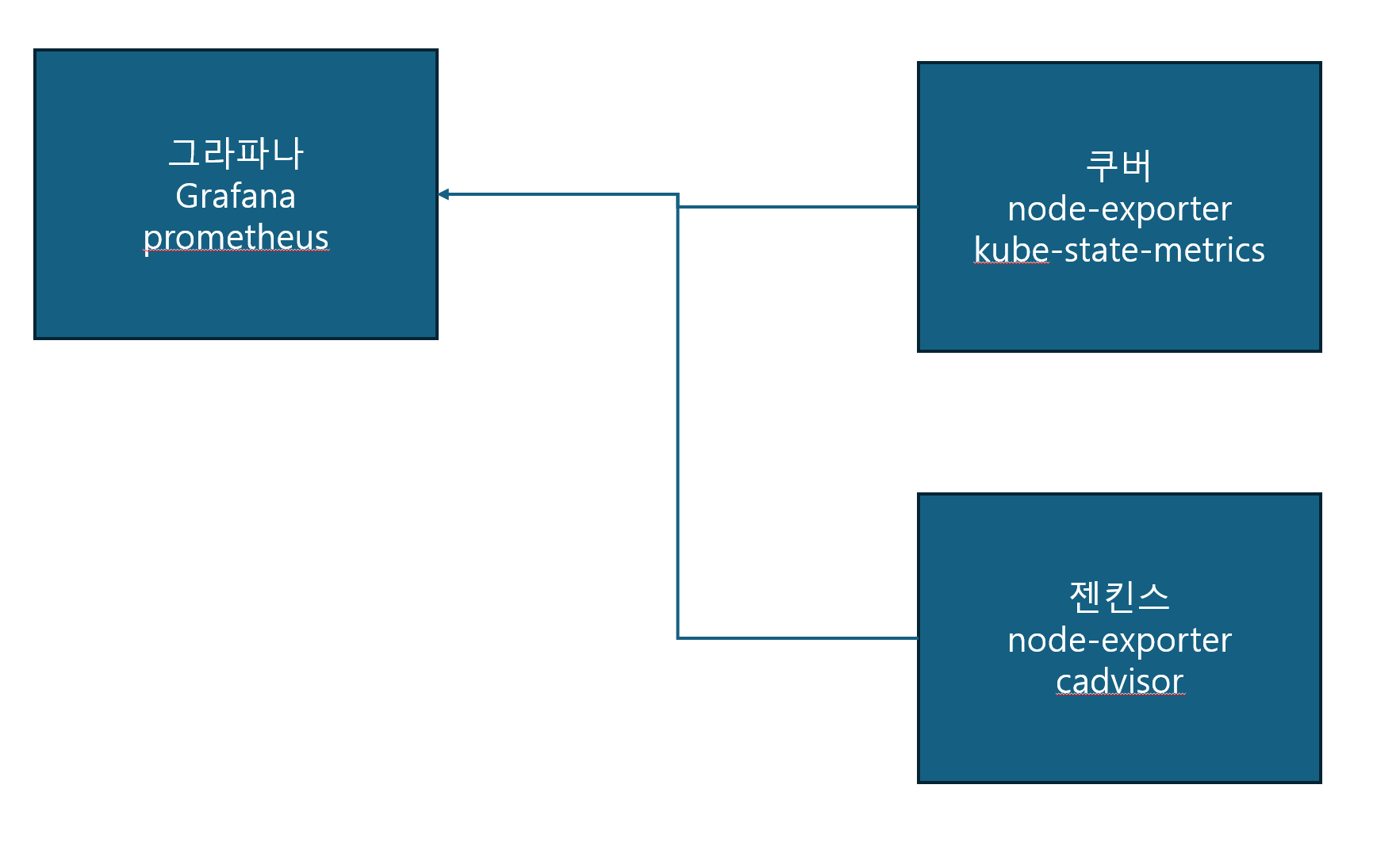
일단 시스템 모니터링의 원리가 어떻게 되냐면
- 쿠버 클라스터에 pod로 설치해 놓은
node-exporter와kube-state-metrics가 시스템 로그(메모리 사용량, pod 상태 등…)을 남겨놓는다. - podman 서버에도
node-exporter와cadvisor가 컨테이너로 설치되어 시스템 로그를 남긴다. node-exporter는 호스트 시스템,kube-state-metrics는 쿠버 내 시스템,cadvisor는 컨테이너 내 시스템을 대상으로 한다.prometheus는 이 로그들을 모아서 한번에 보여주고,promQA라는 쿼리로 가공할 수 있도록 해 준다.grafana는 이prometheus와 연동해 가공된 데이타를 그래프나 표 등으로 보기 쉽게 UI화 해준다.
대충 이런 구조이다. 바로 들어가 보자!
쿠버서버 대상
node-exporter 설치
우선 모니터링용 포드, 서비스 등이 들어갈 monitoring 네임스페이스를 만들어 주고
kubectl create namespace monitoring
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostNetwork: true
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
containers:
- name: node-exporter
image: quay.io/prometheus/node-exporter:latest
args:
- "--path.procfs=/host/proc"
- "--path.sysfs=/host/sys"
- "--web.listen-address=0.0.0.0:9100"
ports:
- containerPort: 9100
hostPort: 9100
name: metrics
volumeMounts:
- name: proc
mountPath: /host/proc
readOnly: true
- name: sys
mountPath: /host/sys
readOnly: true
- name: rootfs
mountPath: /rootfs
readOnly: true
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
---
apiVersion: v1
kind: Service
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
type: NodePort
ports:
- port: 9100
targetPort: 9100
nodePort: 30910
protocol: TCP
name: metrics
selector:
app: node-exporter
이렇게 node-exporter.yaml 파일을 만들어 pod와 서비스를 같이 설치해 주고, 노드포트까지 뚫어 준다.
특이하게 포드를 Deployment가 아닌 DaemonSet으로 설치했는데,
데몬셋은 노드 하나에 포드 1개씩 배치할 때 사용하는 옵숀이다.
디플로이먼트는 쿠버네티스가 생각한 최적의 노드에 포드를 생성하는데, 데몬셋은 그런 거 상관 없이 노드 하나당 포드를 한 개씩 무조건 생성하는 것으로
node-exporter는 호스트, 즉 노드의 시스템을 수집하므로 노드당 하나씩 있어야 하는 것이다.
kube-state-metrics 설치
kubectl apply -f node-exporter.yaml로 설치하는 것 잊지 말고, kube-state-metrics.yaml을 만들고 아래와 같이 지정해 주고
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources:
- pods
- nodes
- namespaces
- services
- resourcequotas
- replicationcontrollers
- persistentvolumeclaims
- persistentvolumes
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- deployments
- daemonsets
- replicasets
- statefulsets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitoring
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitoring
labels:
app: kube-state-metrics
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.16.0
ports:
- name: http-metrics
containerPort: 8080
- name: telemetry
containerPort: 8081
---
apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: monitoring
labels:
app: kube-state-metrics
spec:
type: NodePort
ports:
- name: http-metrics
port: 8080
targetPort: 8080
nodePort: 30911
- name: telemetry
port: 8081
targetPort: 8081
nodePort: 30912
selector:
app: kube-state-metrics
kubectl apply -f kube-state-metrics.yaml 으로 설치해 주자.
노드 익스포터와 달리 ServiceAccount, ClusterRole, ClusterRoleBinding을 추가로 설치하는데,
kube-state-metrics 포드는 클러스터 시스템 수집이 목표라 클라스터 내 접근 권한이 필요하기 때문이다.
ServiceAccount는 포드가 클라스터 내 접근하기 위한 계정을 생성하고ClusterRole은 클러스터 내 어떤 자원에 접근할 수 있는지를 정의,ClusterRoleBinding은 위 클라스터롤을 써비스어카운트에 적용하는 것이다.
그리고 이 포드는 클라스터 시스템 수집이라 노드별로 하나씩 있을 필요가 없으므로 배포 방식이 Deployment이고,
serviceAccountName: kube-state-metrics으로 써비스어카운트와 연결,
실제 데이타를 수집하는 http-metrics와 클라스터 헬스 체크용 telemetry 포트 2개를 사용한다. 마찬가지로 노드포트로 클라스터 외부에 열어 주고
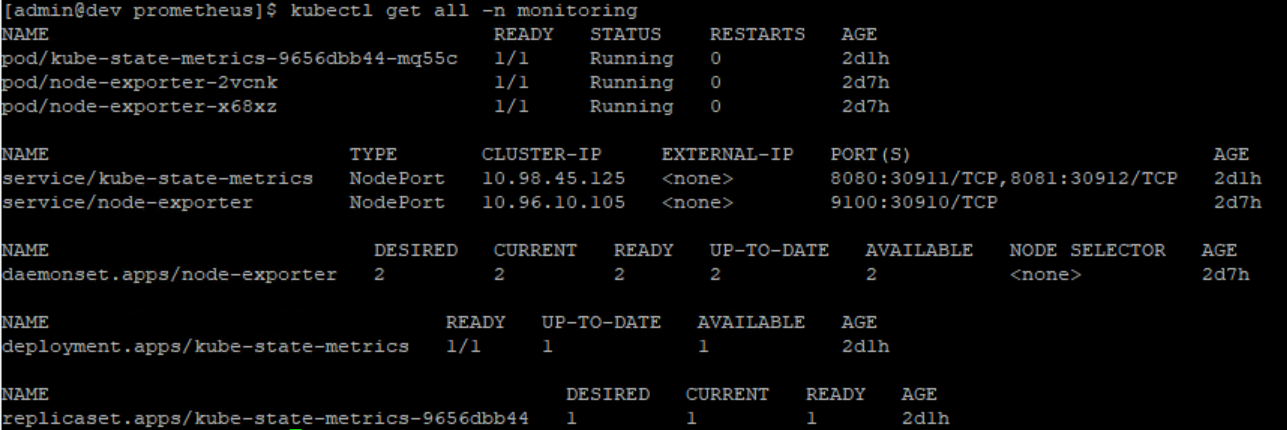
kubectl get all -n monitoring으로 모든 포드와 써비스 등이 올라왔는지 확인해보자!
젠킨스서버 대상
node-exporter, cadvisor 설치
이제 젠킨스 서버(podman 서버)로 이동해서
여기엔 podman-compose가 있기 때문에 node-exporter와 cadvisor를 한꺼번에 설치할 수 있다!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
version: '3.8'
services:
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
ports:
- "9101:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /var/lib/containers/:/var/lib/containers:ro
restart: unless-stopped
privileged: true
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- "9100:9100"
node-exporter의 podman-compose.yaml은 다음과 같다. podman compose up -d로 설치하는 것 잊지 말고~
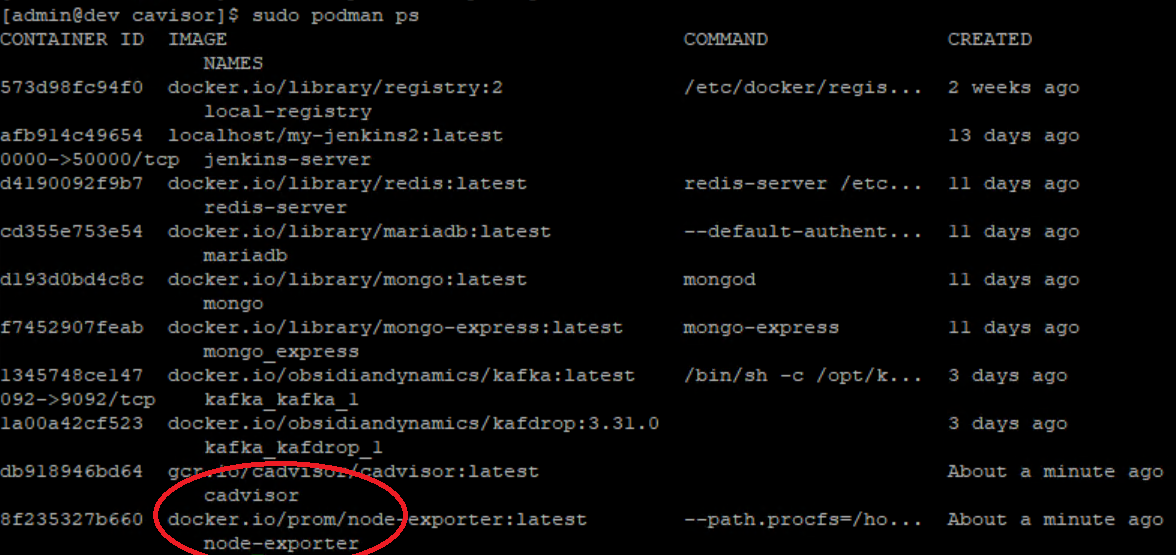
마찬가지로 sudo podman ps로 컨테이너가 올라 왔는지 확인해 주자.
그라파나서버 대상
이제 그라파나와 프로메테우스를 설치할 서버로 가서, 여기에 프로메테우스와 그라파나를 설치해 주자.
당직(当職)은 온프레미스 서버의 포화로 AWS EC2에 서버를 올렸기 때문에, 아까 올려놓은 포드와 컨테이너의 포드 포워딩은 필수다.
내외부 포트포워딩
그라파나 서버를 쿠버/젠킨스 서버와 같은 물리서버에 올릴 것이면 이 문단은 넘어가도 좋다.
호스트 서버의 IP가 192.168.0.222, 쿠버 VM이 192.168.56.100, 젠킨스 VM이 192.168.56.200일 때, 위 yaml 기준으로
- 192.168.0.222:9100→192.168.56.100:30910
- 192.168.0.222:9101→192.168.56.100:30911
- 192.168.0.222:9102→192.168.56.100:30912
- 192.168.0.222:9200→192.168.56.200:9100
- 192.168.0.222:9201→192.168.56.200:9101
이렇게 포트를 열어주었다.
참고로 윈도우 기준 포트포워딩 하는 방법은
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#젠킨스
#방화벽 열기
netsh advfirewall firewall add rule name="Port Forward 9200" dir=in action=allow protocol=TCP localport=9200
netsh advfirewall firewall add rule name="Port Forward 9201" dir=in action=allow protocol=TCP localport=9201
#포트포워딩
netsh interface portproxy add v4tov4 listenaddress=192.168.0.222 listenport=9200 connectaddress=192.168.56.200 connectport=9100
netsh interface portproxy add v4tov4 listenaddress=192.168.0.222 listenport=9201 connectaddress=192.168.56.200 connectport=9101
#쿠버
#방화벽 열기
netsh advfirewall firewall add rule name="Port Forward 9100" dir=in action=allow protocol=TCP localport=9100
netsh advfirewall firewall add rule name="Port Forward 9101" dir=in action=allow protocol=TCP localport=9101
netsh advfirewall firewall add rule name="Port Forward 9102" dir=in action=allow protocol=TCP localport=9102
#포트포워딩
netsh interface portproxy add v4tov4 listenaddress=192.168.0.222 listenport=9100 connectaddress=192.168.56.100 connectport=30910
netsh interface portproxy add v4tov4 listenaddress=192.168.0.222 listenport=9101 connectaddress=192.168.56.100 connectport=30911
netsh interface portproxy add v4tov4 listenaddress=192.168.0.222 listenport=9102 connectaddress=192.168.56.100 connectport=30912
그리고 EC2에서 인터넷을 통해 이 서버에 접근 가능하도록 호스트 서버의 공인 IP를 알아낸 다음,
공유기 설정에서 공인 IP:9100→192.168.0.222:9100 이렇게 공인 IP도 포트를 열어줘야 한다.
보안 문제가 있으니까 반드시 위에서 지정한 포트만 열어주자!
EC2 보안그룹 설정
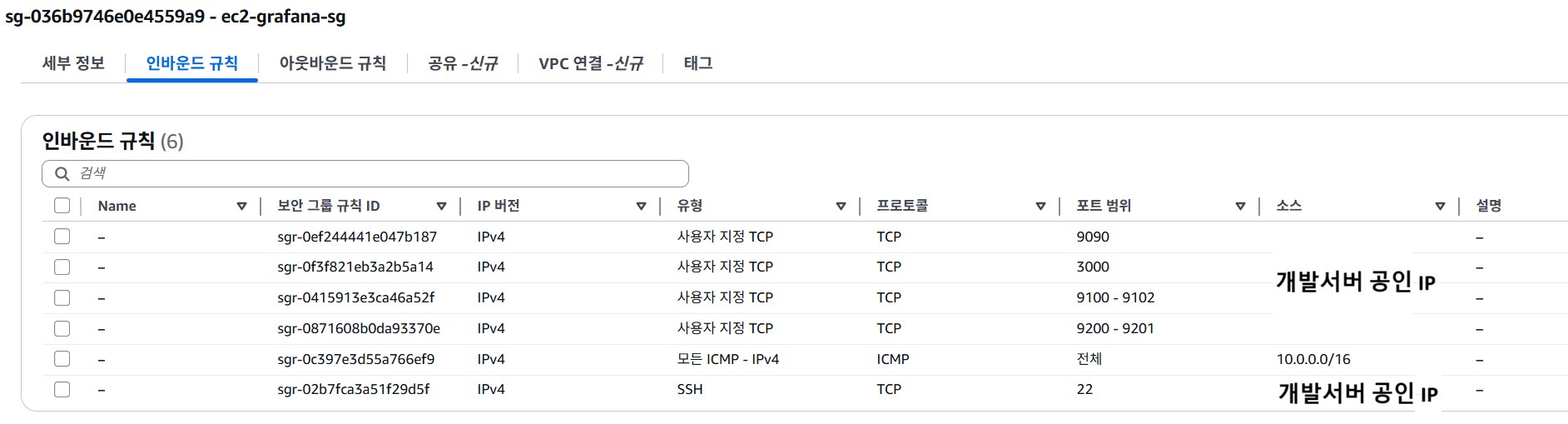
호스트 서버로부터 로그를 모을 프로메테우스 서버가 EC2, 즉 인터넷 상에 있고
포트 포워딩이 (호스트서버 공인 IP)→(호스트서버 내부 IP)→(VM IP) 이렇게 가는 식이므로
프로메테우스가 있을 EC2에서 호스트서버 공인 IP로 요청이 들어오므로 위 사진처럼 인바운드 설정을 해 줘야 한다.
(9090은 프로메테우스 콘솔, 3000은 그라파나 콘솔)
프로메테우스, 그라파나 설치
아마존 리눅스 2023(레드햇 계열) 기준, 그라파나는 기본 yum 레포에 없어서 따로 만들어 줘야 한다.
1
2
3
4
5
6
7
8
9
10
wget -q -O gpg.key https://rpm.grafana.com/gpg.key
sudo rpm --import gpg.key
sudo vi /etc/yum.repos.d/grafana.repo
# grafana.repo작성
sudo yum install grafana
sudo systemctl enable grafana-server --now
[grafana] name=grafana baseurl=https://rpm.grafana.com repo_gpgcheck=1 enabled=1 gpgcheck=1 gpgkey=https://rpm.grafana.com/gpg.key sslverify=1 sslcacert=/etc/pki/tls/certs/ca-bundle.crt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
프로메테우스도 마찬가지로 yum 설치가 되지 않아, 수동으로 설치해줘야 한다.
```bash
curl -O https://github.com/prometheus/prometheus/releases/download/v3.5.0/prometheus-3.5.0.linux-amd64.tar.gz
tar -xvzf prometheus-3.5.0.linux-amd64.tar.gz
sudo mv prometheus-3.5.0.linux-amd64 /opt/prometheus
sudo vi /etc/systemd/system/prometheus.service
# prometheus.service작성
sudo mkdir -p /opt/prometheus/data
sudo systemctl daemon-reload
sudo systemctl enable --now prometheus
[Unit] Description=Prometheus Wants=network-online.target After=network-online.target
[Service] User=root ExecStart=/opt/prometheus/prometheus
–config.file=/opt/prometheus/prometheus.yml
–storage.tsdb.path=/opt/prometheus/data Restart=always
[Install] WantedBy=multi-user.target
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
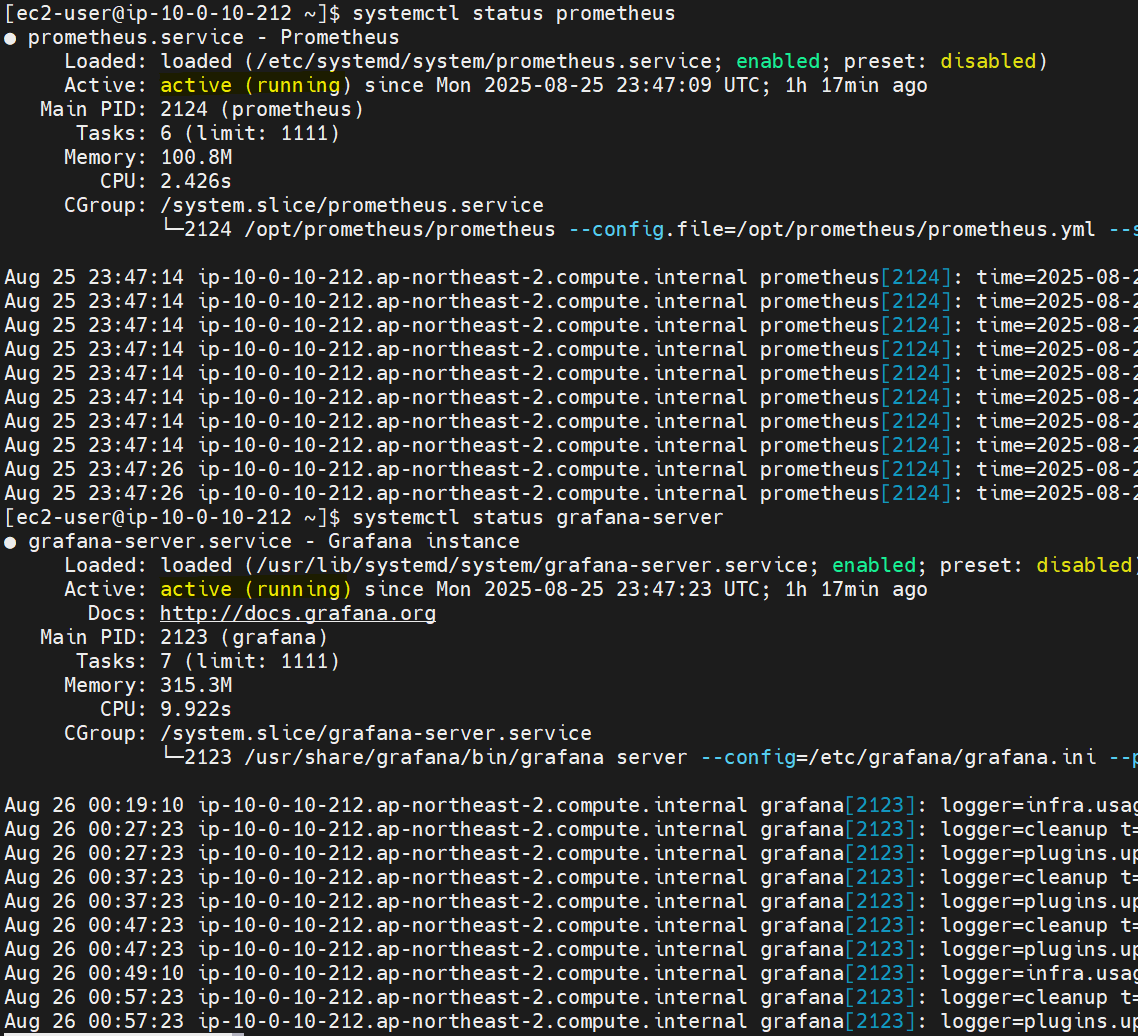
```systemctl status```로 둘 다 올라왔는지 확인해주자.
주의할 점은 그라파나는 ```grafana```가 아닌 ```grafana-server```이다!
## 프로메테우스 설정
### prometheus와 node-exporter, cadvisor, kube-state-metrics 연결
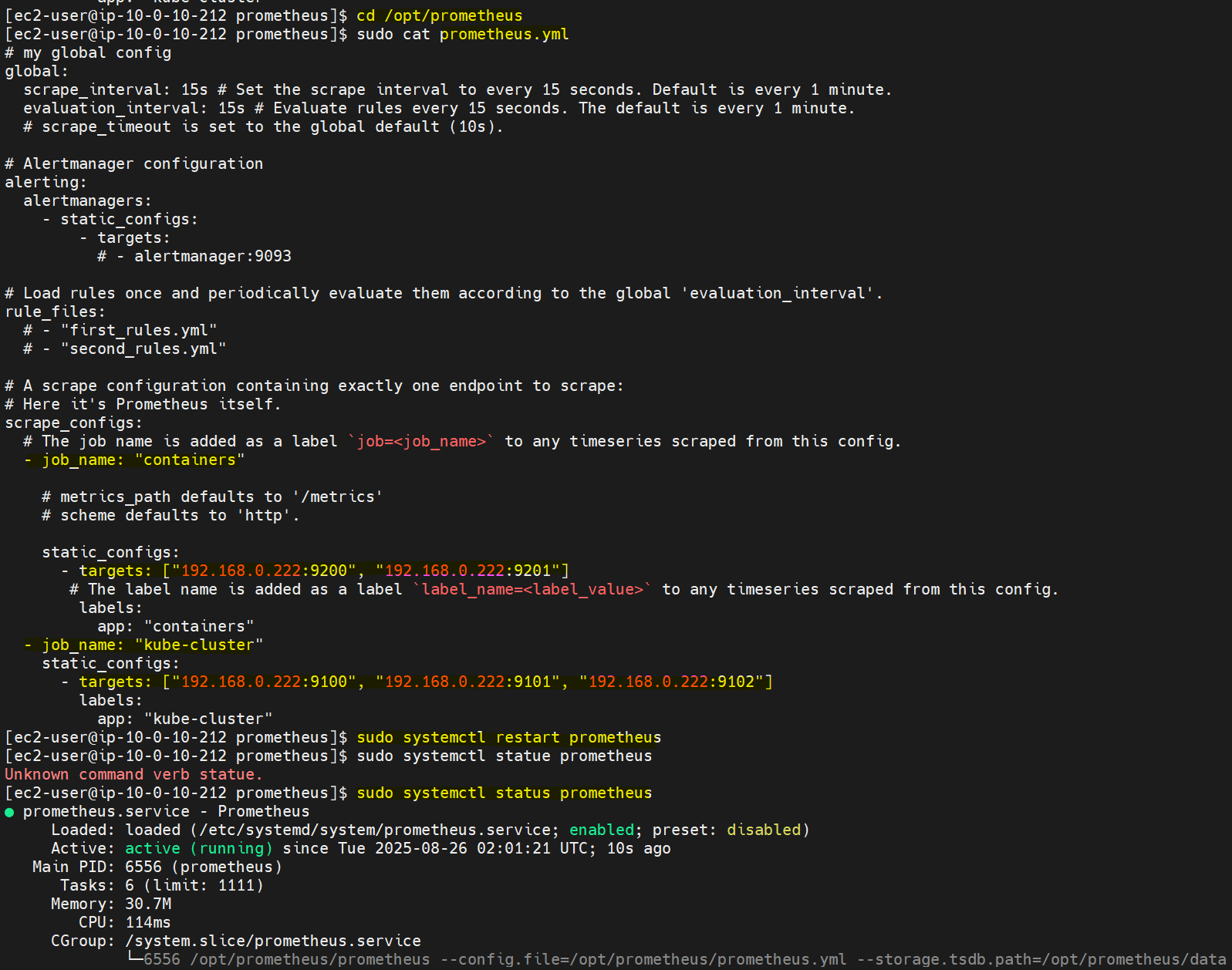
프로메테우스를 설치한 위치(위 기준으론 ```opt/prometheus```)에 ```prometheus.yml``` 파일이 있다.
이 파일에서 아까 설치한 시스템 로그 포드/컨테이너를 연결할 수 있다.
```yaml
scrape_configs:
- job_name: "containers"
static_configs:
- targets: ["(호스트 서버IP-그라파나서버가 EC2라면 공인IP):9200", "(마찬가지):9201"]
labels:
app: "containers"
- job_name: "kube-cluster"
static_configs:
- targets: ["(마찬가지):9100", "(마찬가지):9101", "(마찬가지):9102"]
labels:
app: "kube-cluster"
cluster: "kube-cluster"
이런 식으로 scrape_configs 아래 아까 포트 포워딩한 로그 주소와 포트를 targets 배열에 넣고
이왕이면 job_name으로 컨테이너와 쿠버를 구분해 주는 게 좋다. 나중에 promQA 쿼리 짤 때 편리해지거든
마찬가지로 쿠버 job_name의 경우 labels: 내 cluster: 이름도 지정해 줘야 promQA가 수월해진다.
sudo systemctl restart prometheus로 재시작 해 주면 연결이 된다!
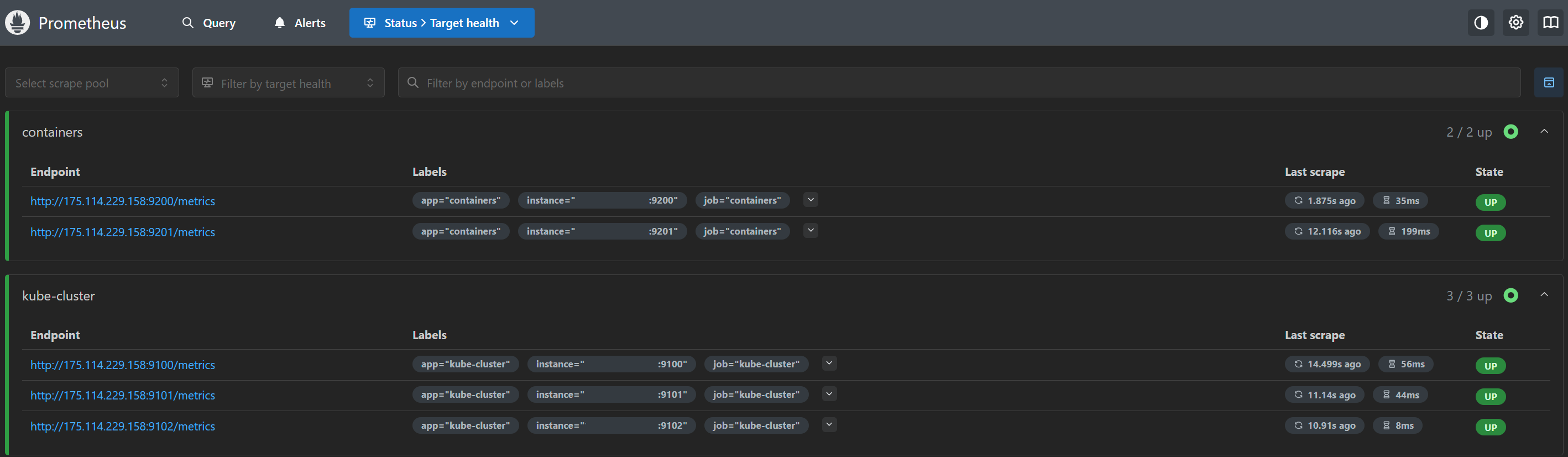
그라파나서버 주소:9090으로 UI 접속한 다음 상단 Status→Target Health 항목에서 모두 연결이 되었는지 확인한다.
(당직은 EC2가 그라파나 서버이기 때문에 공인IP-검열처리)
grafana와 prometheus 연결
그라파나는 그라파나서버 주소:3000으로 연결 가능하다.
초기 아이디와 비밀번호는 모두 admin이니까 로그인 해 주면
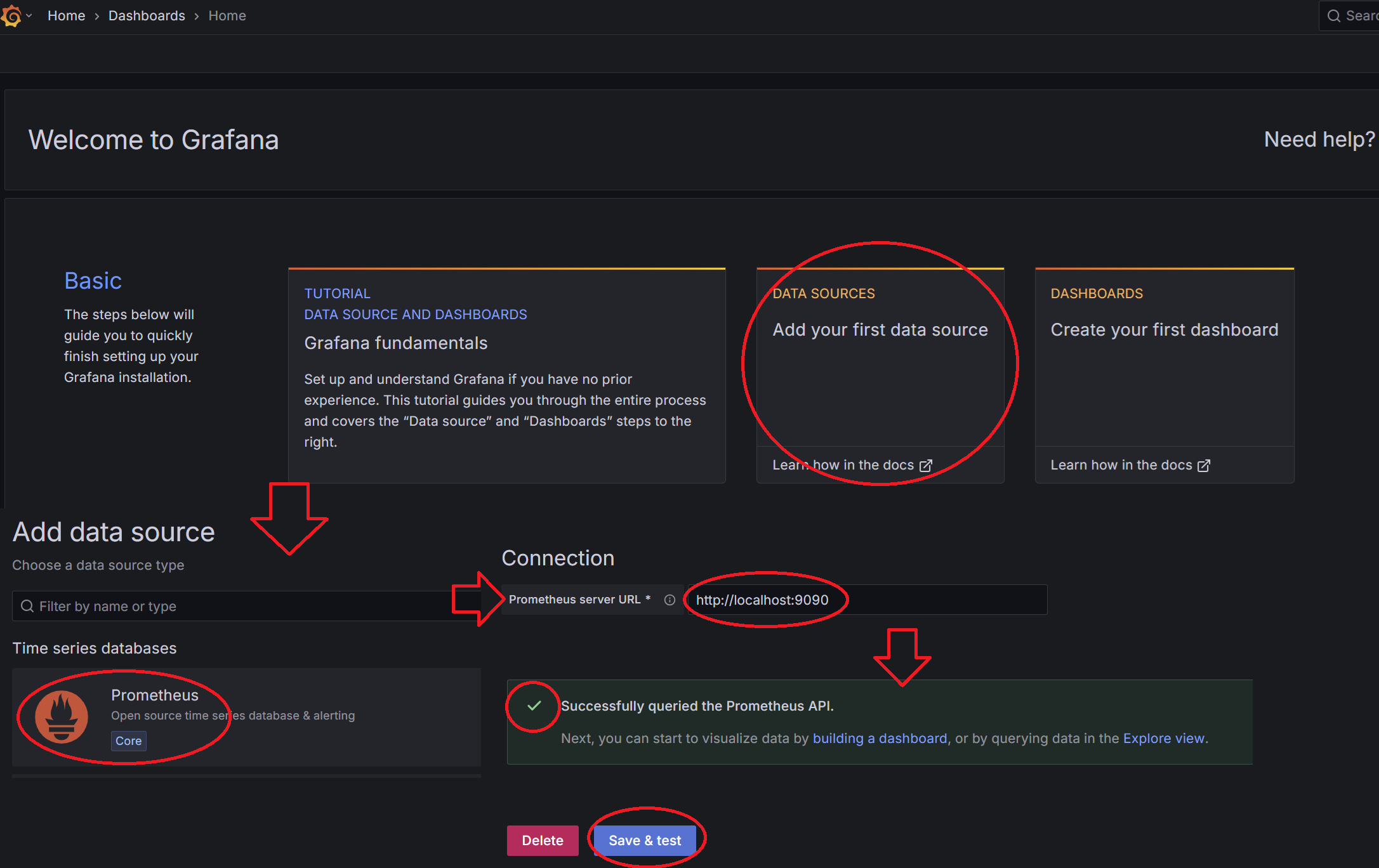
이런 홈 화면이 나오는데
- DATA SOURCES를 클릭하고
- Prometheus를 선택
- Prometheus server URL에 http://localhost:9090을 입력하고(같은 서버에 있으니까)
- Save&test를 클릭하면 그라파나와 프로메테우스 연결 성공!
그라파나 대쉬보드 불러오기
프로메테우스 정보는 이렇게 몽고db같은 데이타의 연속이라 이걸 UI적으로 표현해 주는 것이 그라파나이다.
UI를 표현하려면, 대쉬보드를 만들어줘야 한다.
그런데 그라파나는 고맙게도 여러 사용자들이 게임 MOD처럼 자신만의 대쉬보드를 공유해 주기 때문에
우리는 쿠버 및 젠킨스(도커) 전용으로 미리 만들어진 대쉬보드를 각각 가져와 사용할 것이다.
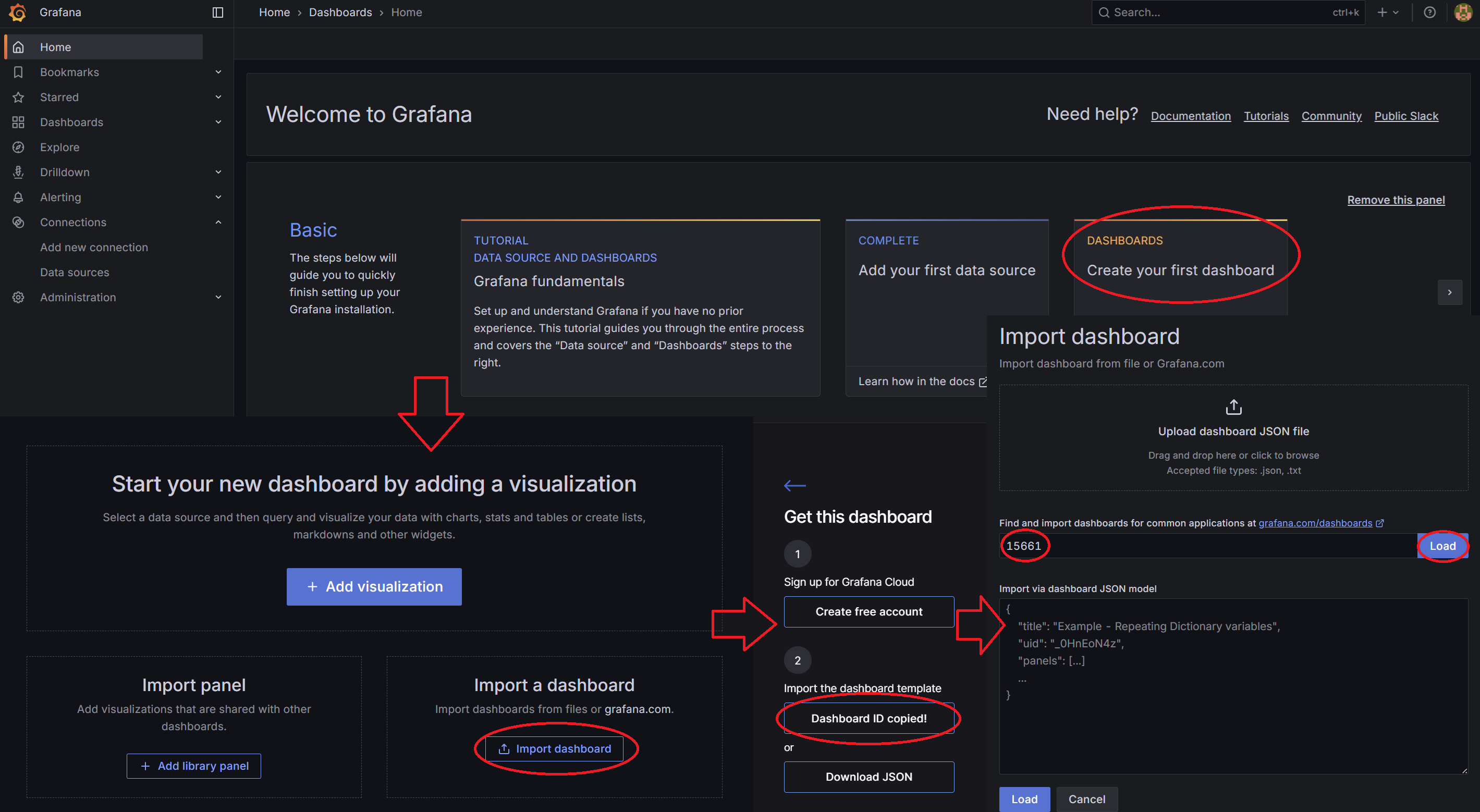
대쉬보드를 가져오는 방법은 홈 화면으로 가 DASHBOARDS를 클릭한 다음 Import dashboard 클릭,
대쉬보드 아이디를 가져와야 하는데,
당직은 쿠버는 여기,
젠킨스는 여기
에서 가져왔다.
가져오는 방법은 위 주소에 들어가서 우측의 Copy ID to clipboard를 클릭하고,
Find and Import dashboards.. 란에 붙여넣기 한 뒤 우측 Load 버턴을 클릭하면 된다.
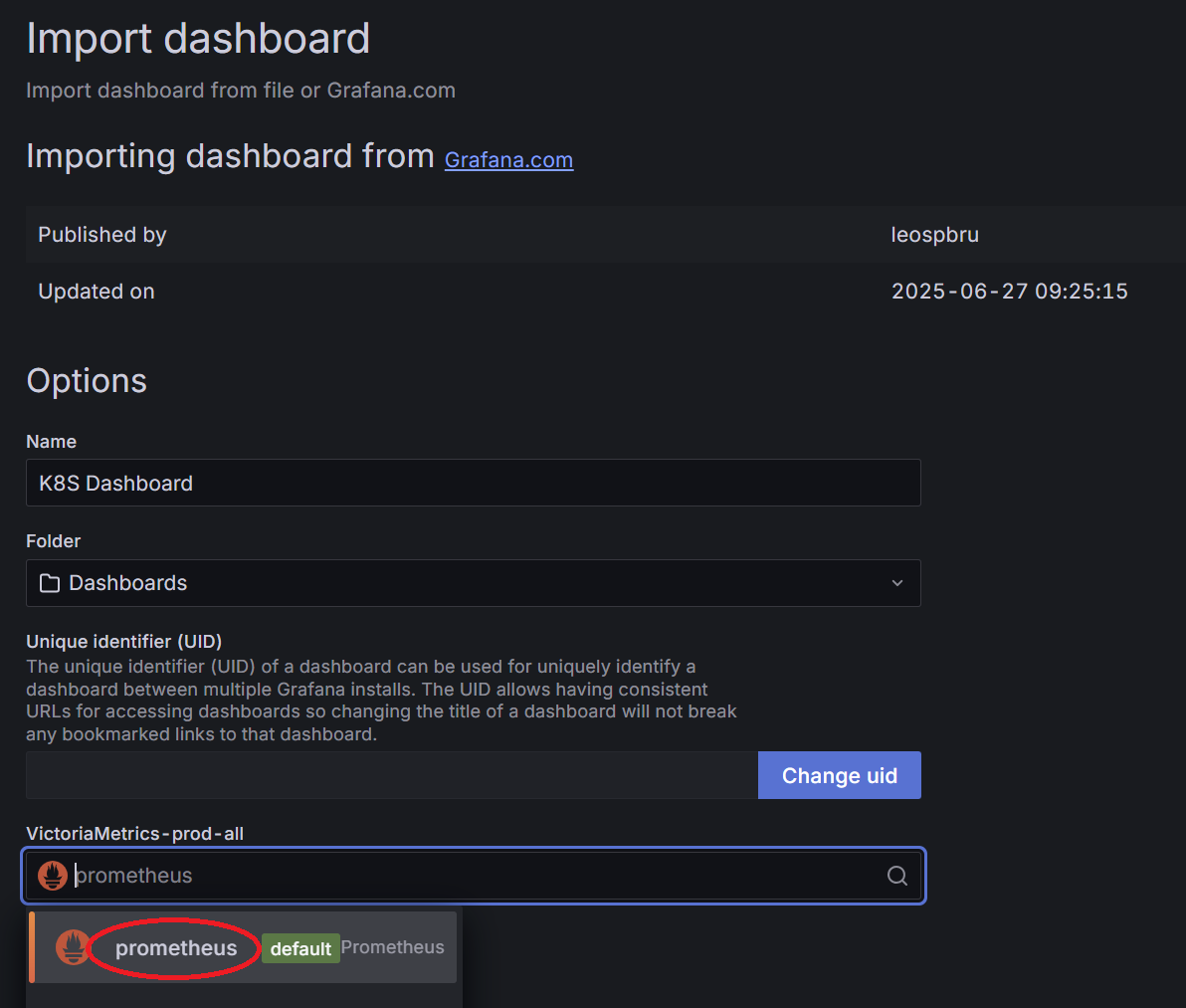
누르면 Import Dashboard 창이 뜨는데, 아래 선택창에 아까 연결한 prometheus를 선택하고 확인 하면…
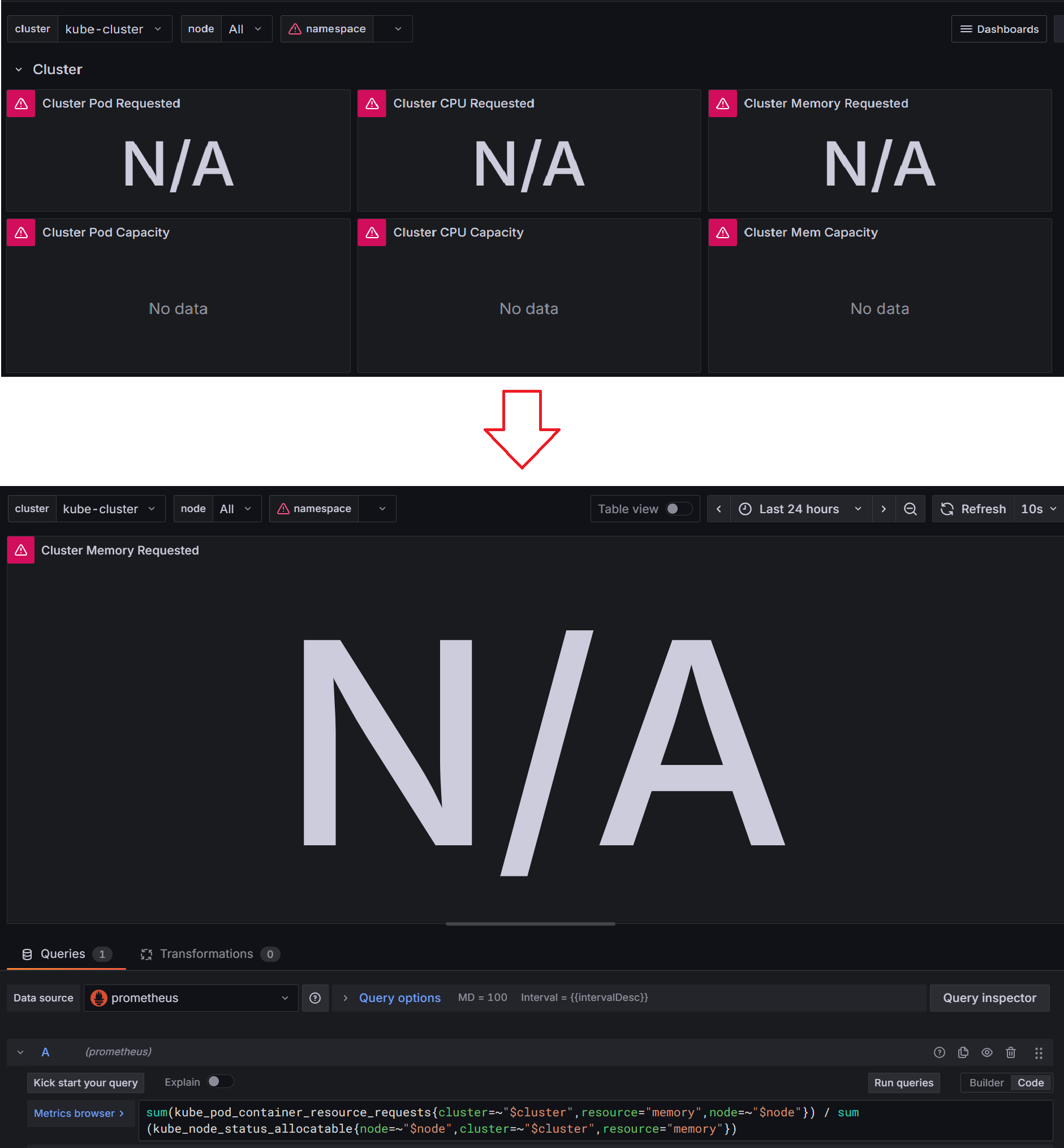
역시나 한 방에 될 리가 또 없다. 이건 가져온 쿠버 대쉬보드 자체의 문제인데,
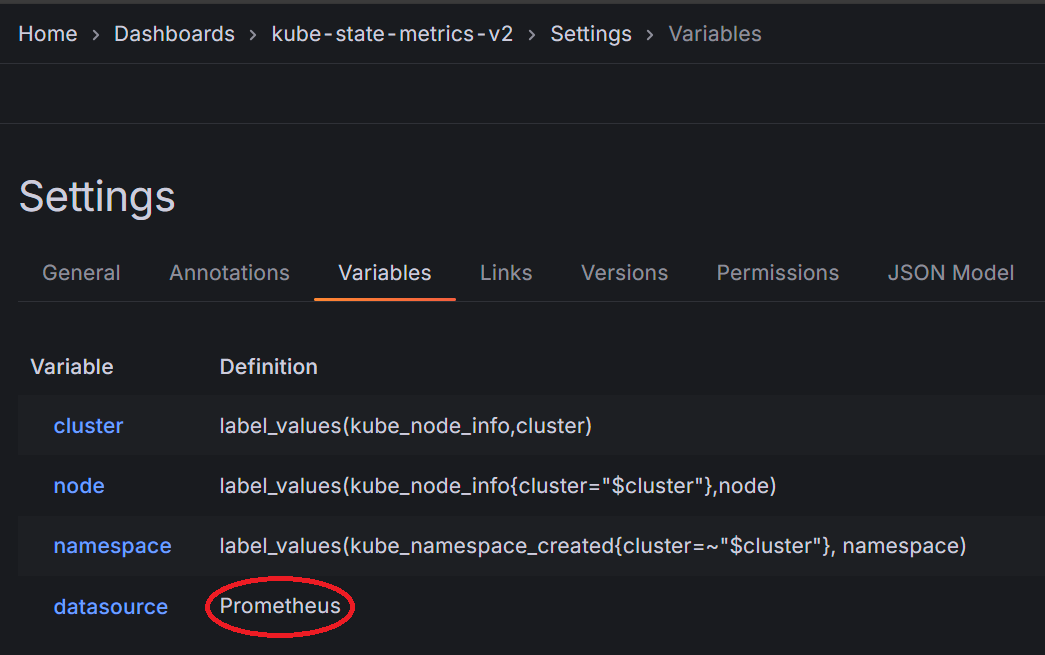
대쉬보드 우측 상단 edit→settings에 들어가(edit 버튼을 누르면 settings 버튼이 나옵니다)
Variables 탭에 가면 이 대쉬보드에서 사용하는 변수가 나와 있다. 여기서는 datasource 변수값이 Prometheus로 되어 있는 게 문제였는데,
아까 프로메테우스 연결할 때 이름이 prometheus, 즉 소문자로 되어 있어서 연동이 안 된 것이다.
이름을 소문자로 바꿔 주니까..
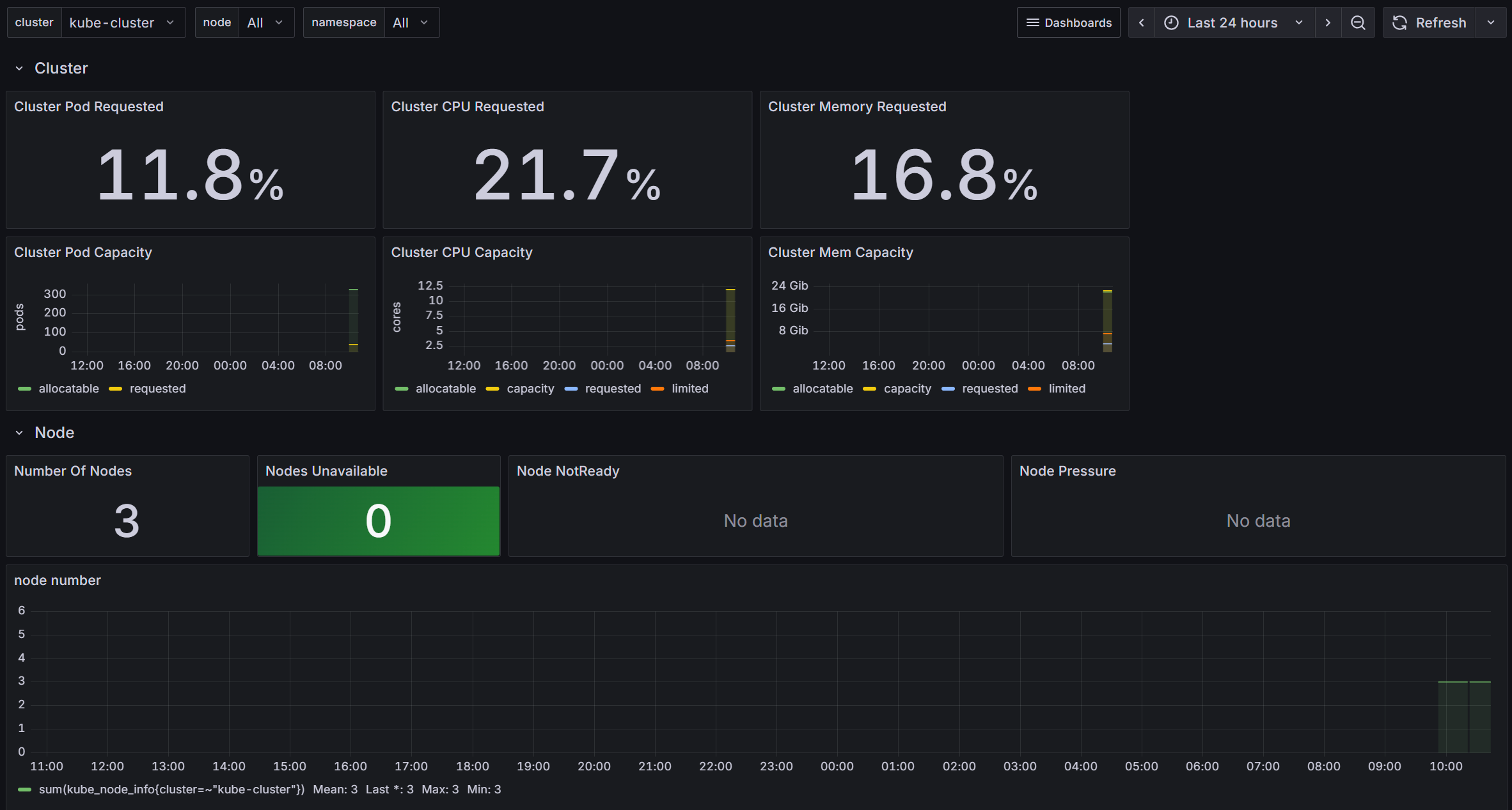
된다!!
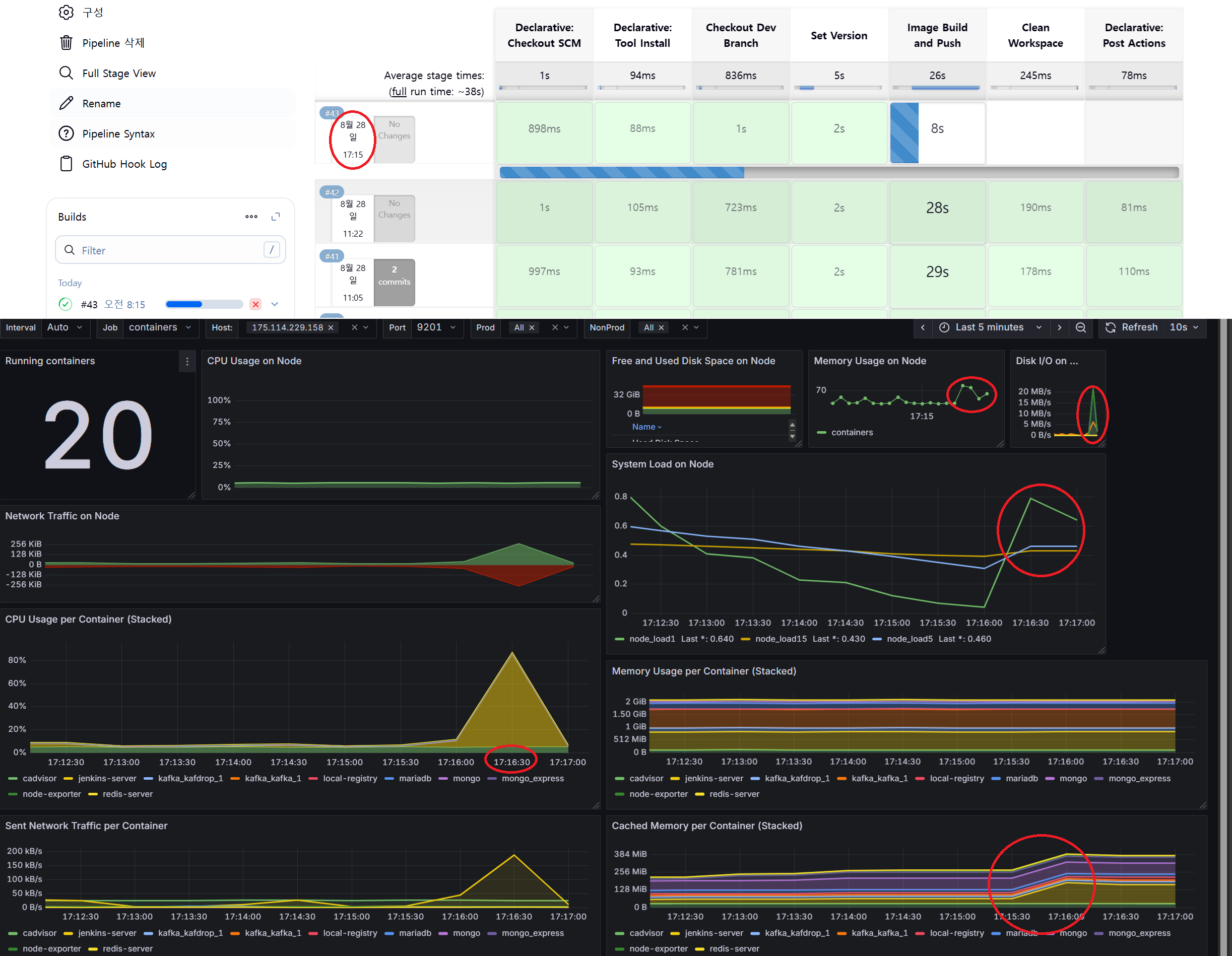
젠킨스(컨테이너) 대쉬보드도 이렇게 올라와, 젠킨스 작업이 있을 때마다 자원이 올라가는 것을 확인할 수 있다!
promQA 간략 사용법
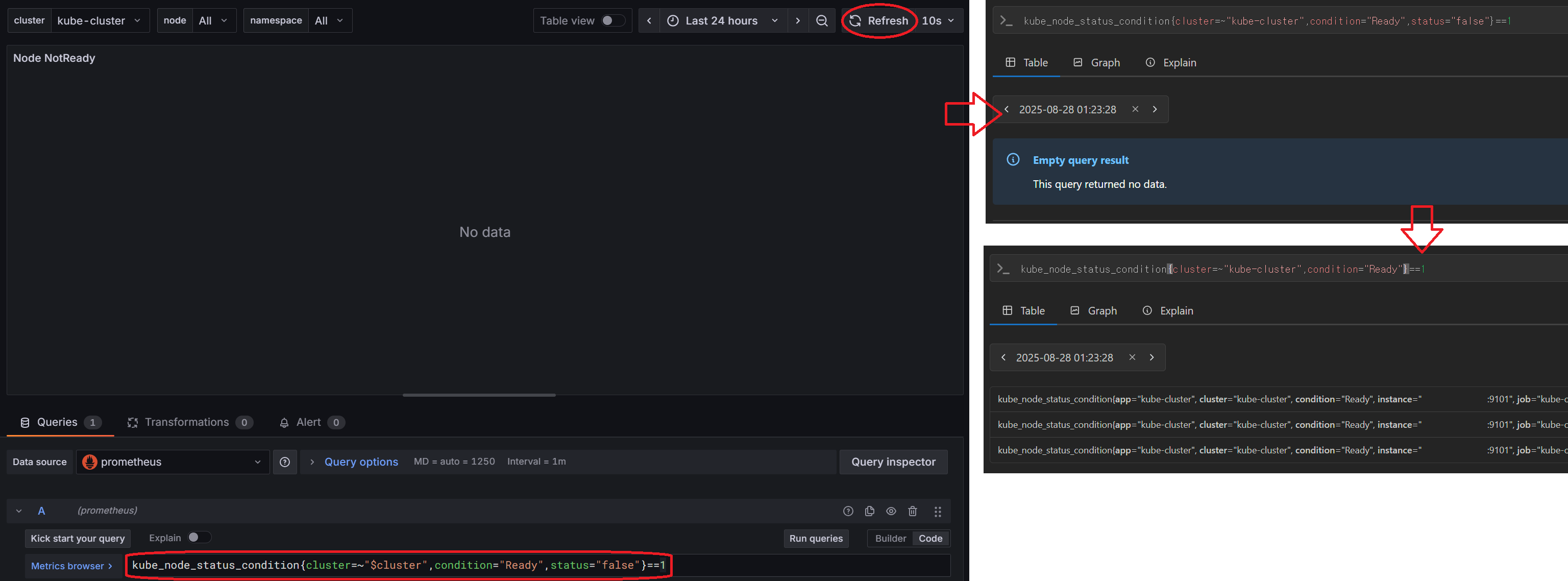
물론 이 대쉬보드가 내 환경에 맞춰 나온 것이 아니기 때문에, 사진처럼 안 보이는 항목들도 있다.
이런 항목들을 해결하기 위해선 대쉬보드를 이루는 promQA를 역설계하면 되는데..
- 각 항목을 클릭해 해당되는 promQA 쿼리문을 본다.
- 해당 쿼리문을
그라파나서버 주소:9090, 즉 프로메테우스 서버로 가서 테스트해볼 수 있다. - 쿼리문의 파라메타({} 안에 있는 것들)을 하나씩 지우거나 바꿔 가며 데이타가 나오는지 확인해 본다.
- 아까
prometheus.yml의 쿠버 job_name에 cluster를 넣으라는 이유도, 쿠버 대쉬보드의$cluster변수가 cluster 파라메타를 사용하기 때문이다. 없으면 쿼리 결과에 cluster가 나오지도 않는다.
위 사진의 경우에는 status 파라메타가 전부 true여서 데이타가 나오지 않는 것이였다.
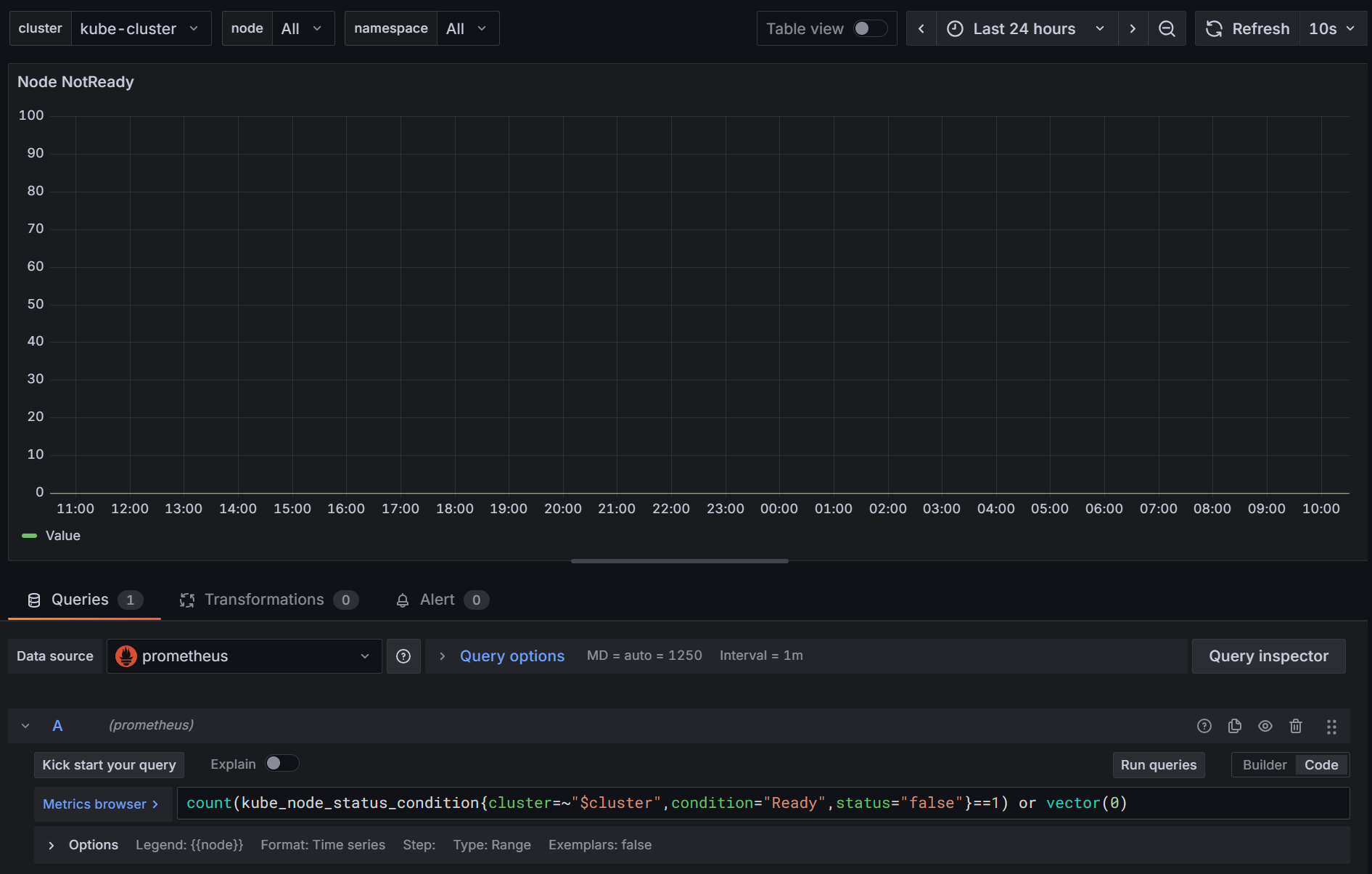
쿼리 뒤에 or vector(0)을 붙여 주면 없을 때 0으로 표시하라는 내용이 추가, 0이 나온다!
좌충우돌 promQA 튜닝은 다음 포스트에서 더 자세히 다뤄 보겠다.