프로젝트 좀보이드(Project Zomboid) 서버 고도화① - Openstack 클러스터 구축
서버 재구축하기
지난번에 구축한 Hyper-V 기반 게임 서버는 뭔가 개선점이 필요했다. 그 이유를 몇개 들면
- Windows 라이센스 여분이 없다
- 호스트가 메모리를 많이 잡아먹는다(가만히 있어도 4GB 정도?)
- VM 사이즈(CPU/MEM)를 수정하려면 껐다 켜야 한다…
그래서 서버를 리눅스 기반으로 재구축하기로 했고, 몇 가지 가상화 툴을 알아보다가 Openstack이라는 오픈 소스 프로젝트를 발견했다.
Openstack이란?
Openstack은 Openstack 재단(현재는 OpenInfra Foundation)이라는 곳에서 운영하는 오픈소스 기반의 클라우드 컴퓨팅 플랫폼이다.
간단히 말해 방구석 컴퓨터를 AWS 같은 클라우드 서비스(IaaS)처럼 구성하고 제어할 수 있게 해주는 거대한 시스템인 것이다.
단순한 가상화 프로그램을 넘어 자원(컴퓨팅/네트웤/스토리지)을 논리적으로 분리하고 웹 콘솔 또는 API로 유연하게 관리할 수 있어서, 프라이빗 클라우드를 구축할 때 사실상의 표준으로 쓰인다.
클라우드란?
여기서 클라우드에 대해 다시 한번 짚고 가자면, 똑똑해진 가상 자원 관리 방법이라 보면 되겠다.
기존의 Hyper-V에서 VM이나 네트웤을 수정하려면 호스트에 들어가 일일이 직접 수정해줘야 하지만(VM과 네트웤를 껐다 켜야 한다는 점도),
클라우드 환경에서는 API나 웹 콘솔 클릭 몇 번으로 중단 없이 편리하게 수정할 수 있는 것이다.
클라우드의 3대 요소는 바로 컴퓨팅/네트웤/스토리지이다.
- 컴퓨팅: 연산을 수행하는 요소로 보통 CPU/RAM을 뜻한다.
- 네트웤: 연결을 담당하는 요소로 NIC(랜카드), 라우터(공유기) 등이 있다.
- 스토리지: 데이터를 저장하는 요소로 블록 스토리지/오브젝트 스토리지 등이 있다.
(gemini 나노바나나 너무 좋아!)
프라이빗 클라우드
프라이빗 클라우드는 말 그대로 개인 용도, 즉 외부에 개방되어있지 않은 전용 클라우드를 뜻한다.
나만의 클라우드이기 때문에 보안이나 각종 규제에 민감하게 대처할 수 있어, 보통 기업이나 기관 등지서 사내 서버를 구성할 때 많이 사용한다.
대표적으로 VMWare ESXi, Red Hat Virtualization 등이 프라이빗 클라우드를 제공하는 솔루션이다.
당연하겠지만 반대말은 퍼블릭 클라우드로, AWS 같이 누구나 인터넷을 통해서 사용할 수 있는 클라우드를 뜻한다.
질문? 그럼 프라이빗 클라우드랑 온-프레미스랑 사실상 같은 의미 아닌가요?
당직(当職)도 처음 들었을 땐 많이 헷갈렸는데, 위에서 말한 것처럼 자원 관리를 유연하게 할 수 있는가의 차이로 생각하면 되겠다.
Openstack의 구성 요소
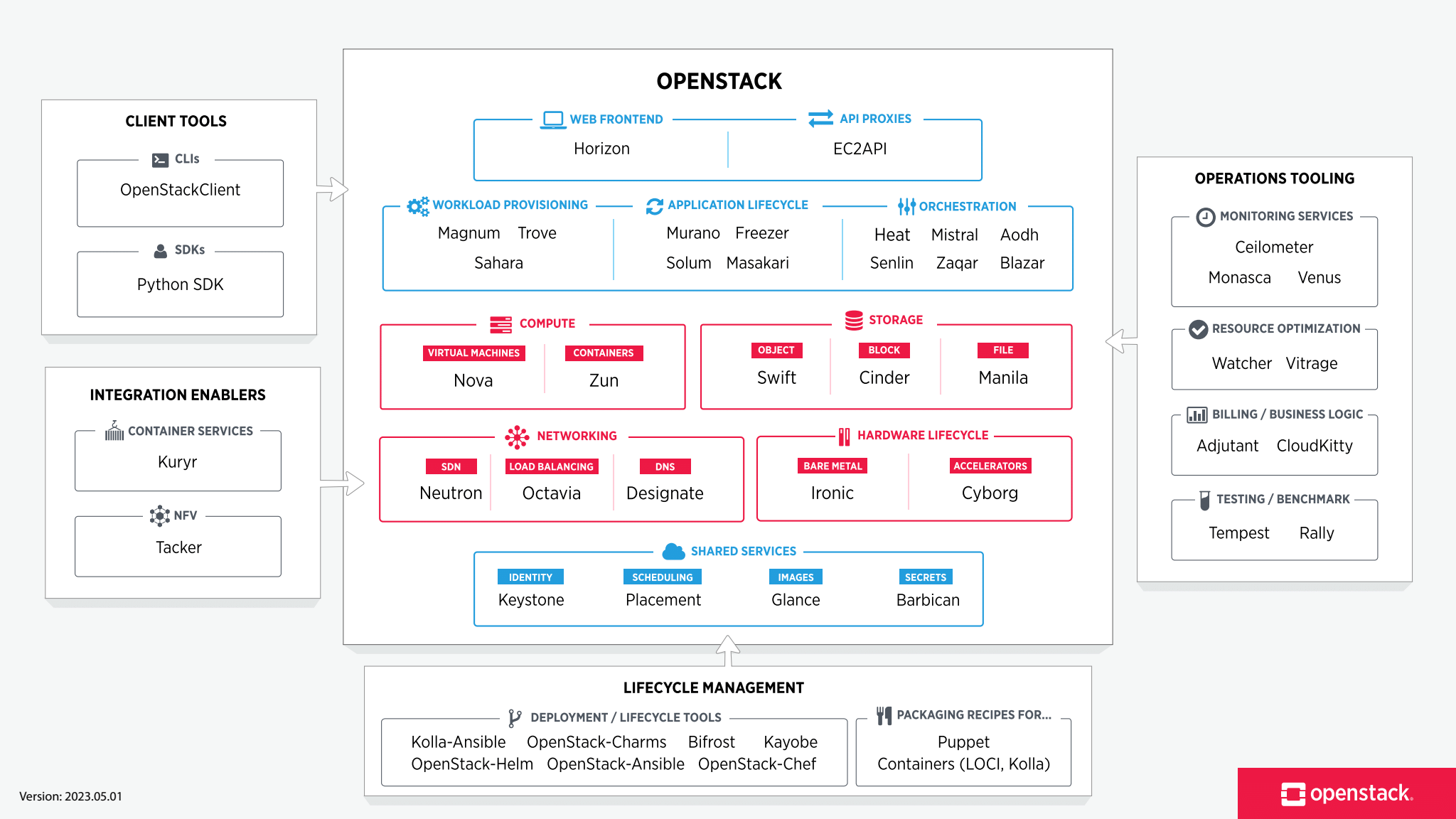
Openstack은 Nova, Neutron, Cinder 등 각종 서비스들이 뭉친 덩어리와도 같은데, 위 사진만 봐도 머리가 어지러워지니 좀 있다 하기로 하고
우선 물리적인 요소로 보면 콘트롤러 노드와 콤퓨트 노드가 있다.
콘트롤러 노드, 콤퓨트 노드
콘트롤러 노드는 Openstack 클러스터를 관리하는 서버이다.
사용자의 요청을 API를 통해 받아들이고, 데이터베이스(MariaDB 등)와 메시지 큐(RabbitMQ 등)를 통해 전체 클러스터의 상태를 기록하고 명령을 내린다.
인증 관리(Keystone)과 웹 콘솔(Horizon) 같은 관리용 서비스들이 주로 이곳에서 돌아간다.
콤퓨트 노드는 실제 인스턴스(VM)이 들어가고 작동하는 서버이다.
콘트롤러 노드의 명령을 받아 하이퍼바이저(가상 서버 엔진. 윈도우에서는 Hyper-V, 리눅스에서는 KVM이 대표적)를 통해 물리 서버의 CPU와 메모리 자원을 쪼개서 가상 머신을 생성하고 실행한다.
우리가 띄울 좀보이드 VM도 최종적으로는 이 콤퓨트 노드에서 돌아가는 것이다.
뭔가 기시감을 느끼지 않았는가? 그렇다. 쿠버네티스의 마스터-슬레이브 노드의 관계와 비슷하다!
다시 Openstack의 구성 요소
이제 소프트웨어적인 요소로 보면 대표적으로
- 컴퓨팅(VM)을 담당하는 nova
- 네트웤을 담당하는 neutron
- (블록)스토리지를 담당하는 cinder
- 가상 머신 이미지를 담당하는 glance
- 클러스터 내 인증 및 권한을 담당하는 keystone
등이 있는데, 당직은 이 서비스들 간의 관계를 고깔해파리에 비유했다.

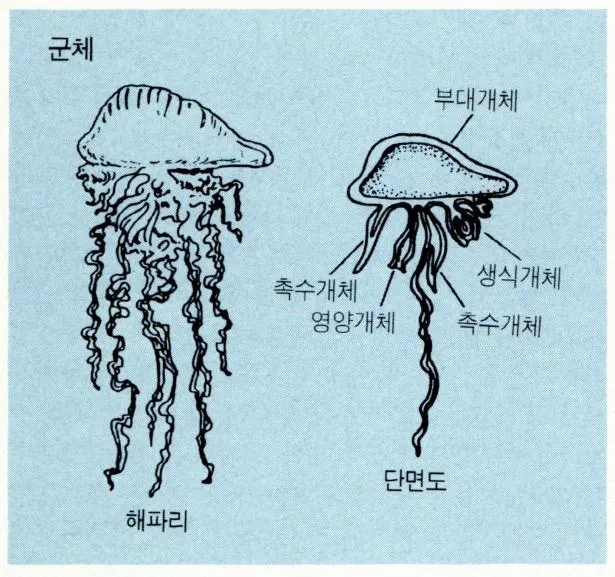
위 유튜브 영상에도 나와있듯이, 고깔해파리는 하나의 생물이 아닌 군체 생물로
생식만을 담당하는 생물과, 이동(부레)을 담당하는 생물, 먹이를 잡는 촉수 생물 및 영양을 공급하는 소화 생물이 모여 하나의 고깔해파리를 형성한다.
각 객체는 별개의 생물이지만 정해진 역할을 수행하는 것처럼,
Openstack도 컴퓨팅만 담당하는 요소(nova), 네트웤만 담당하는 요소(neutron) 등이 모여 하나의 클러스터를 구성하는 것이다.
Openstack 클라스터가 VM을 생성하는 과정
(사전 지식) nova는 세부적으로
- 요청을 처리하는 nova-api
- 콤퓨트 노드를 선택하는 nova-scheduler
- 가상 서버를 실제로 생성하는 nova-compute
- nova-compute가 수행한 내용을 db에 저장하는 nova-conductor
로 구성되고, 세부요소를 포함 각 요소들 간의 통신은 메세지 큐를 통해, 모든 상태값(VM 사양, 볼륨 크기 등)은 db에 저장된다.
그럼, 이 요소들이 어떻게 각자의 역할을 수행할까? VM(가상서버)를 생성하는 과정을 들자면
(콘트롤러 노드)
- nova-api가 사용자의 가상 서버 생성 요청을 받는다.
- nova-api가 이를 메세지 큐에 추가하고, nova-scheduler가 서버를 생성할 적절한 콤퓨트 노드를 선택한다. (콤퓨트 노드)
- 선택된 콤퓨트 노드에 있는 nova-compute가 하이퍼바이저를 통해 가상 서버를 생성한다.
- 이 때 nova-compute는 glance에서 이미지를 가져오고, cinder에서 스토리지를 할당하며, neutron에서 네트웤을 설정하도록 요청을 보낸다. (콘트롤러 노드)
- nova-conductor가 생성된 가상 머신 정보를 DB에 저장한다.
가상 서버 생성은 nova의 담당 영역이니 nova가 주로 수행하지만,
4번에서처럼 네트웤과 스토리지, 이미지에 관련해서는 cinder, neutron의 힘을 빌릴 수밖에 없다.
또한 각 요소들은 고깔해파리처럼 별개의 객체이므로 요소들 간 통신에는 “이놈이 우리 클러스터의 객체가 맞는지”를 확인하는 과정이 필요한데, 이를 담당하는 것이 keystone이다.
즉 4번 과정에서 nova-compute가 neutron에게 네트웤 생성을 요청하면
neutron은 먼저 keystone을 통해 “아, 우리 클러스터의 nova-compute가 맞구나!”를 안 다음 네트웤 생성을 수행한다.
다음 시간에는 openstack 단일 클러스터 구성을 실제로 해 보겠다~